Section 1: The AI Trust Paradox in Health Economics and Outcomes Research
Health Economics and Outcomes Research (HEOR) stands at a critical inflection point. The transformative potential of artificial intelligence promises to revolutionize how we conduct systematic literature reviews, synthesize vast datasets, and develop economic models. Yet despite efficiency gains that could redefine project timelines and resource requirements, widespread adoption within the HEOR community remains hesitant. This reluctance stems not from technological aversion, but from a deeply rooted commitment to scientific rigor that creates what we term the AI Trust Paradox: the profound efficiency gains offered by AI are constrained by necessary skepticism of its reliability, resulting in an implementation stalemate that prevents meaningful progress.
Here I try to examine the components of this paradox, quantifying the trade-off between efficiency and reliability that currently constrains HEOR organizations. I explore the unique, high-stakes risks of AI-generated errors within health economics and analyze why current monolithic approaches to AI implementation fundamentally conflict with established scientific methodology. The logical response to AI unreliability—complete human review—paradoxically negates the technology's core value proposition, creating a cycle of costly and unproductive evaluation.
The Efficiency-Reliability Tension
The fundamental challenge in AI adoption lies in the substantial gap between theoretical efficiency and practical reliability. The potential for acceleration is considerable: analyses indicate that AI-assisted workflows in document-intensive HEOR tasks, such as literature screening and data extraction, and health economic modelling can significantly reduce human workload. For a field where systematic literature reviews often require months of effort from highly skilled teams, such efficiency gains represent a fundamental shift in operational capacity.
However, this potential encounters significant resistance from the research community. Recent surveys reveal that 77% of healthcare professionals cite the immaturity of AI tools as a primary barrier to adoption, followed by financial constraints (47%) and regulatory uncertainty (40%). This skepticism reflects legitimate concerns about the opaque nature of current AI models. For HEOR professionals trained in transparency, validation, and reproducibility principles, the "black box" characteristics of large language models that cannot articulate their reasoning processes directly conflict with established scientific norms.
This fundamental misalignment forces a difficult choice: embrace technology that may compromise research integrity or maintain traditional methods while forgoing revolutionary efficiency gains. The majority of HEOR organizations are choosing to wait, leaving the promised value of AI largely unrealized.
The Unique Challenge of Hallucination in Health Economics
In generative AI contexts, errors are often termed "hallucinations"; outputs that appear plausible and confident yet are factually incorrect or baseless. While problematic in any domain, hallucinations pose uniquely severe consequences in HEOR, where analytical outputs directly inform critical decisions regarding drug pricing, reimbursement, and patient access. Errors are not merely factual inaccuracies; they represent potential threats to public health and economic stability.
The specific forms of hallucination that threaten HEOR require domain expertise to detect:
- Quantitative Misrepresentation: An AI tasked with summarizing clinical trial results might correctly identify a pivotal study but subtly misreport key endpoints. For example, stating a hazard ratio as 0.65 when it was 0.75, or misrepresenting confidence intervals, thereby fabricating statistical significance. Such errors could fundamentally alter the perceived therapeutic value within economic models.
- Methodological Conflation: When synthesizing evidence for cost-effectiveness models, AI might describe a study using partitioned survival methodology but incorrectly attribute Markov model assumptions to it. This creates methodologically incoherent summaries that could mislead human modelers into building flawed analyses based on erroneous precedent.
- Citation Fabrication: Perhaps most commonly, AI may generate non-existent citations to support claims. An AI might state that a specific patient-reported outcome instrument has been validated in a disease population and support this with fabricated references, complete with plausible author names and journal titles. Undetected, this could lead to inappropriate data inclusion in regulatory or health technology assessment submissions.
These HEOR-specific risks necessitate verification that extends beyond simple fact-checking to deep, contextual, methodological review by senior experts, the very resource AI was intended to preserve.
The Failure of Monolithic AI in Scientific Paradigms
Current AI implementation approaches can be characterized as monolithic: deploying single, general-purpose large language models for complex, end-to-end research functions as if they were junior analysts. This paradigm fails in scientific environments because it lacks the layered oversight, validation, and iterative review that characterize rigorous research. While commercial applications can tolerate 80% accuracy, HEOR requires near-perfect reliability where even single, undetected errors can invalidate entire analyses.
The Prohibitive Cost of Complete Review
Faced with hallucination risks and monolithic system failures, the only professionally responsible approach for Principal Investigators is mandating 100% human verification of AI-generated outputs. While ensuring quality control, this systematically dismantles the technology's primary value proposition. Efficiency gained through AI-generated initial drafts is lost in subsequent, painstaking manual review processes.
AI-powered platforms claim to offer significant efficiencies; for example, the EY Document Intelligence platform reports it can help clients "decrease costs by 80%" for document review and processing. This creates a counterproductive cycle: organizations invest in AI to save time and resources, but lack of trust necessitates review processes so resource-intensive that they eliminate anticipated returns on investment. Even in mature applications like AI-powered medical scribes, error rates of 20-30% requiring physician correction remain common, demonstrating that even constrained tasks require substantial oversight.
This paradox leaves HEOR teams in an untenable position. Ignoring AI risks obsolescence, while adopting it under current paradigms leads to unacceptable quality compromises or inefficient workflows. The fundamental issue is not AI technology itself, but implementation models that fail to replicate the trust and verification principles fundamental to scientific inquiry. A new framework is required, one that builds oversight and validation directly into AI workflows, transforming them from fallible black boxes into transparent, structured, and trustworthy research partners.
Section 2: Hierarchical Research Teams: The Proven Model for Quality Control
The AI Trust Paradox stems from a fundamental misalignment: monolithic AI implementation lacks the layered oversight and validation inherent to scientific methodology. To build trustworthy AI frameworks, we must examine not computer science innovations, but the very structure of human-led research that has successfully ensured quality for decades. The solution lies in replicating a proven system: the hierarchical research team.
For generations, scientific inquiry has been organized into tiered accountability and expertise structures. This model represents a deliberately evolved system designed to manage complexity, mitigate error, and ensure robust, defensible, and valid conclusions. Understanding why this human-centric model works effectively provides a clear blueprint for designing AI systems that earn, rather than demand, HEOR community trust.
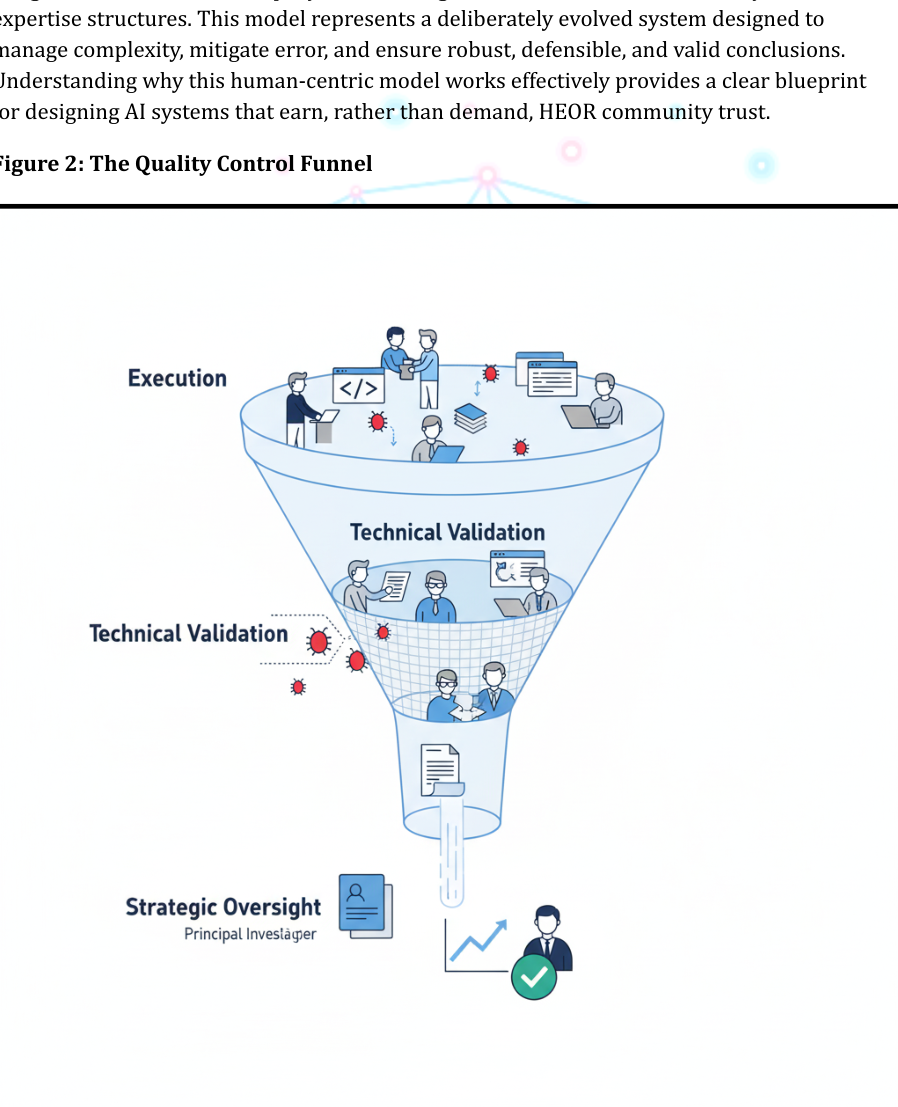
The Architecture of Scientific Rigor: Roles and Responsibilities in HEOR Teams
Research output integrity directly correlates with the team that produces it. In HEOR, teams are typically organized into three-level hierarchies, with each level holding distinct responsibilities for execution, validation, and strategic oversight. This labor division ensures multiple expert perspectives examine research at critical development stages. Standard structures comprise Principal Investigators, senior-level researchers or biostatisticians, and junior-level analysts or research coordinators.
The Principal Investigator (PI) / Research Lead: At the hierarchy apex, PIs hold ultimate accountability for scientific integrity, strategic relevance, and ethical conduct. Their role is primarily architectural rather than executional, serving as study architects and final arbiters. Key responsibilities include:
- Strategic Direction: Defining research questions, establishing study objectives, and designing overall methodological approaches.
- Scientific Oversight: Reviewing and approving final study protocols, interpreting key results, and ensuring conclusions are evidence-supported.
- Stakeholder Communication: Serving as primary contacts for clients, regulatory bodies, and HTA agencies, with responsibility for defending research findings.
PI review represents the final and most critical quality gate, focusing more on setting the strategic direction and whether resulting analyses correctly and meaningfully answer core research questions.
The Senior Researcher / Biostatistician: This mid-level role bridges PI strategic vision with junior team technical execution. These seasoned methodology, statistics, and programming experts ensure technical and methodological research soundness. Responsibilities include:
- Methodological Translation: Converting PI high-level study designs into detailed statistical analysis plans (SAPs) and technical specifications.
- Technical Validation: Conducting rigorous reviews of code, statistical outputs, and data manipulations performed by junior analysts through deep, line-by-line verification processes.
- Mentorship and Guidance: Providing technical leadership and training to junior team members, ensuring adherence to best practices and standard operating procedures.
Senior researchers function as primary technical validators. Their approval signifies work completion with accurate execution according to approved protocols.
The Junior Analyst / Research Coordinator: Forming the foundational team layer, junior analysts handle day-to-day research plan execution. Their work provides raw material for final research outputs. Key responsibilities include:
- Execution: Performing tasks such as literature screening, data extraction, statistical model programming, and generating tables and figures.
- Initial Quality Control: Conducting self-review and initial work validation to identify and correct errors before advancing to the next level.
- Documentation: Maintaining clear, comprehensive records of all procedures, code, and data sources to ensure transparency and reproducibility.
While executional, this role provides the first and most fundamental quality control defense line. Their work quality directly impacts the entire review hierarchy efficiency and effectiveness.
Distributed Quality Control: A Multi-Layered Review Process
The hierarchical model's strength lies not only in defined roles but in systematic work and review flow between levels. Quality control is not a single event but a continuous, distributed process where each layer provides different scrutiny types. This multi-layered approach creates review process redundancy, making it highly resilient to individual human error.
Initially, junior analysts perform self-checks, ensuring code runs error-free and outputs appear plausible. Work then advances to senior researchers, who conduct comprehensive technical and methodological reviews analogous to formal peer review within teams. Senior researchers validate logic, check for statistical errors, and ensure analyses faithfully implement SAPs, asking "Was this done correctly?"
Only after technical validation completion does the work product reach PIs. PIs perform final strategic and scientific reviews, assessing outputs within broader research question contexts, scrutinizing result interpretations, and ensuring scientific narrative coherence. PIs ask, "Does this make sense, and does it answer our question?" This separation of concern is profoundly efficient. PIs are freed from time-consuming code review, trusting senior researcher validation, and can focus expertise on higher-level scientific implications.
This system effectively prevents single points of failure. Coding errors missed by junior analysts are typically caught by senior researchers. Subtle methodological flaws might be identified during technical review. Misinterpretations of statistically significant results are likely corrected by PIs. This layered defense underpins traditionally conducted research reliability.
Scaling Quality: From Single Studies to Multi-Center Trials
One of the hierarchical structure's most powerful attributes is inherent scalability. As research projects grow in complexity, from single economic models to global, multi-center clinical trials, this model allows oversight delegation without sacrificing quality control. Single PIs cannot personally review every case report form or data point from thousands of patients across dozens of sites. Instead, quality control functions are distributed through nested hierarchies.
Good Clinical Practice (GCP) principles, governing clinical trial conduct, formally codify this scalable hierarchical model. Overall PIs for multi-center trials rely on sub-investigators at participating sites, who oversee clinical research coordinators managing daily data collection. Quality is ensured through standardized protocols, regular monitoring visits, and data audit trails.
This framework demonstrates how tiered structures allow single accountability points (PIs) to effectively manage quality across vast, complex operations. PIs need not review everything because they can trust validated processes and delegated sub-investigator authority. The system scales because review burden is distributed, with each level responsible for manageable oversight scopes. This scalable, distributed trust principle is precisely what current monolithic AI implementations lack and is essential for building systems that operate reliably in complex research environments.
Section 3: Introducing the LLM-as-a-Judge Framework: Architecture and Principles
The Three-Tier Architecture: A Digital Mirror of the Research Team
The LLM-as-a-Judge framework is not single software but an operational architecture designed to emulate successful research team quality control mechanisms. It organizes AI agents into functional hierarchies mirroring junior analyst, senior researcher, and PI roles, ensuring no AI-generated output reaches humans for strategic review without first undergoing rigorous, automated validation.
- Tier 1: The AI Worker (The Executor): This foundational layer parallels the junior analyst. The AI Worker is a large language model optimized for generative tasks and throughput. Its primary function is execution at scale: drafting clinical trial publication summaries, extracting data points from tables, generating initial statistical model code, or screening thousands of literature search abstracts. The Worker is designed for speed and breadth.
- Tier 2: The AI Judge (The Validator): This intermediate layer represents the framework's core innovation, serving senior researcher or biostatistician functions. The AI Judge is a distinct large language model configured specifically for evaluating AI Worker output. It does not generate new content; it critiques existing content. The Judge receives Worker output, original source material, and explicit quality criteria. It then assesses output for accuracy, source fidelity, and methodological standard adherence.
- Tier 3: The Human Researcher (The PI): At the hierarchy apex remains the human expert. The PI's role is elevated from tedious, line-by-line verification to high-level strategic oversight and scientific judgment. Instead of receiving raw, untrustworthy AI output, researchers receive curated packages: AI Worker drafts, AI Judge detailed critiques, and highlighted discrepancies.
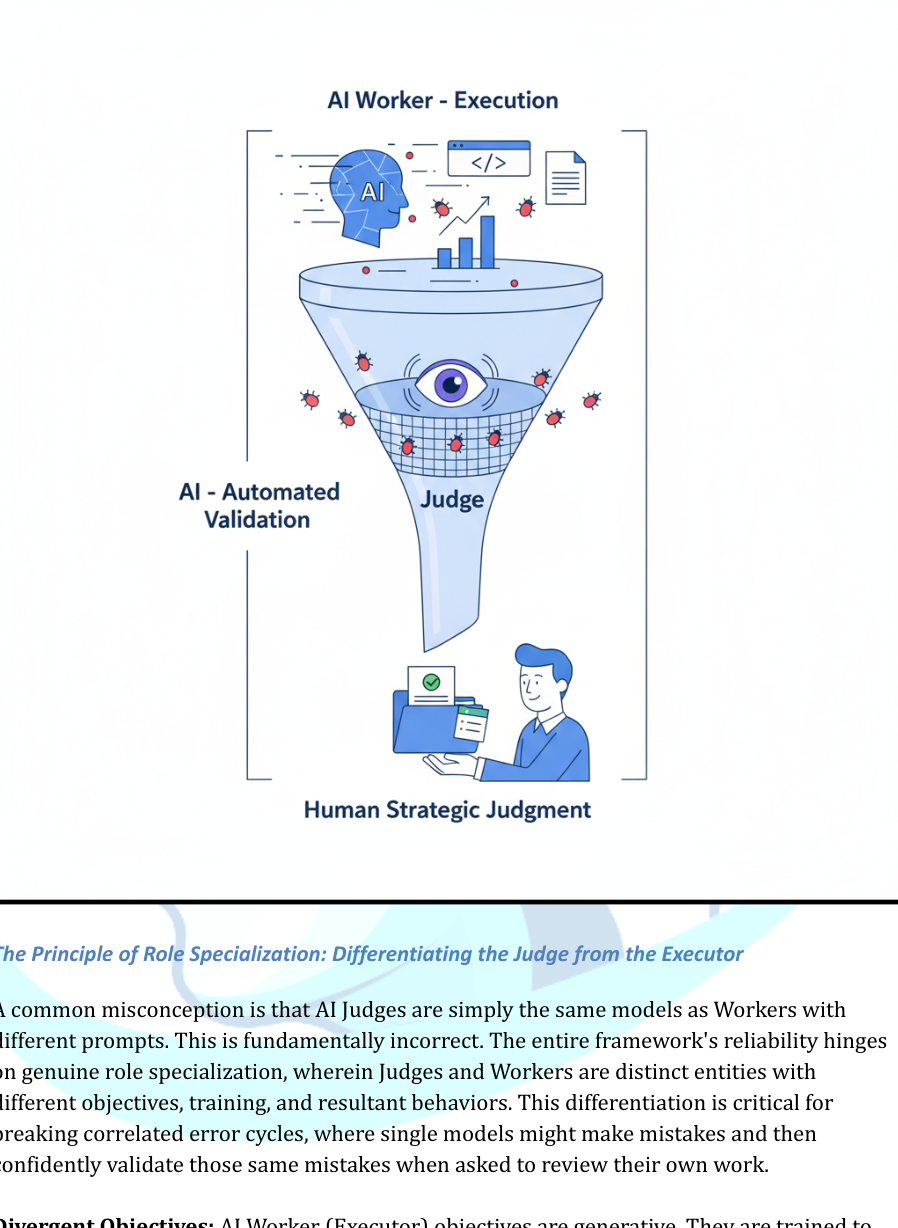
The Principle of Role Specialization: Differentiating the Judge from the Executor
A common misconception is that AI Judges are simply the same models as Workers with different prompts. This is fundamentally incorrect. The entire framework's reliability hinges on genuine role specialization, wherein Judges and Workers are distinct entities with different objectives, training, and resultant behaviors. This differentiation is critical for breaking correlated error cycles, where single models might make mistakes and then confidently validate those same mistakes when asked to review their own work.
Divergent Objectives: AI Worker objectives are generative. They are trained to predict the next most plausible word in sequences, enabling fluent text production. This plausibility optimization creates hallucination vulnerability. Conversely, AI Judge objectives are evaluative. They are tasked to identify discrepancies between two text pieces or classify outputs against quality standard rubrics. Their goal is not creation but flaw detection.
Specialized Configuration and Training: While both Worker and Judge roles may utilize the same foundational large language model, their operational objectives must diverge significantly. This specialization can be achieved through different levels of investment and technical sophistication—from carefully designed prompts that establish distinct evaluative personas to fine-tuning on curated validation datasets. Regardless of the implementation approach, separating generative and evaluative functions creates productive tension that significantly reduces the likelihood of unchecked errors reaching human reviewers.
Core Principles for Systemic Reliability
The LLM-as-a-Judge framework architecture and role specialization give rise to operating principles that make the system inherently more reliable than monolithic AI approaches.
- Automated Layered Review: The framework institutionalizes mandatory, automated peer review for every AI-generated content piece. Unlike manual spot-checking, AI Judges systematically scrutinize every AI Worker output.
- Transparency through Chain-of-Thought Reasoning: Well-designed AI Judges do not simply render binary verdicts (e.g., "correct" or "incorrect"). They provide reasoning through "chain-of-thought" validation processes. This transparency demystifies AI decision-making.
- Focused Human Expertise: By filtering out significant portions of basic errors, the framework ensures human attention is reserved for the most complex and nuanced issues. This dramatically reduces cognitive load on senior researchers and mitigates "review fatigue".
Essential Competencies for an HEOR-Specific AI Judge
For the LLM-as-a-Judge framework to be effective in HEOR, AI Judges must be equipped with specific domain-relevant competencies. Generic fact-checking approaches are insufficient.
- Quantitative Verification: The ability to extract numerical data from tables and text in source documents and verify accurate reporting in AI Worker summaries.
- Methodological Scrutiny: The capacity to identify study designs, statistical methods, and patient populations described in sources and flag any mischaracterizations.
- Citation Integrity Auditing: The skill to check whether cited references support linked propositions through contextual content checks.
- Guideline Adherence Checking: Assessing generated outputs against established HEOR reporting guidelines, such as CHEERS-AI checklists.
Conclusion: From AI Tools to AI Systems
The central irony of AI adoption in HEOR has become increasingly apparent: technology promised to liberate researchers from tedious manual work, yet many organizations now find themselves worrying that they may spend more time reviewing AI-generated outputs than they would have spent doing the work manually. This is not an indictment of artificial intelligence itself, but rather a symptom of flawed implementation paradigms. The AI Trust Paradox persists not because large language models lack capability, but because so far we have mostly deployed them as isolated tools rather than as components of thoughtfully designed systems.
The solution to this paradox lies not in waiting for more advanced AI models, but in recognizing that trustworthy AI adoption is fundamentally a systems design challenge. The blueprint for reliable AI implementation already exists within HEOR organizations themselves: the hierarchical research team structure. By deliberately translating these principles into AI architectures, we can transform fallible generative models into trustworthy research partners.
The LLM-as-a-Judge framework acts as one implementation of this broader principle: that reliable AI systems require built-in adversarial validation, not post-hoc human correction. It introduces automated validation layers that mirror the senior researcher's technical review function, preventing errors from reaching human experts who can then focus on strategic scientific judgment.
The path forward does not require waiting for artificial general intelligence. It requires applying the organizational and methodological wisdom that HEOR professionals already possess. By translating the proven principles of hierarchical research teams into AI system architectures, we can resolve the AI Trust Paradox and unlock AI's promise: not to replace human expertise, but to amplify it, accelerating the generation of high-quality evidence that improves patient outcomes and advances global health.
Download the Full Paper
Get the PDF version with complete references for offline reading and sharing with your team.
Developed by Aide Solutions LLC. This white paper was prepared with the support of generative artificial intelligence tools. The author reviewed, edited, and takes full responsibility for the content and conclusions presented. Full references are available in the PDF version.