The GenAI Failure Epidemic: Validating Professional Skepticism
If you're skeptical about generative AI, you're not being irrational, you're reading the data correctly.
The enterprise GenAI failure rate isn't a matter of debate or anecdotal disappointment. MIT's NANDA Initiative recently analyzed over 300 organizational AI implementations and conducted 52 detailed interviews with executives. Their conclusion: 95% of enterprise GenAI pilots deliver zero measurable return on investment [1]. This finding isn't an outlier. NTT DATA reports 70-85% of GenAI deployments fail to meet ROI expectations [2]. Gartner predicts 30% of GenAI projects will be abandoned after proof-of-concept by the end of 2025 [3]. The RAND Corporation, analyzing 65 structured interviews with experienced data scientists and engineers, found that 80% of AI projects fail, double the failure rate of traditional IT projects [4].
For health economists and outcomes research professionals accustomed to evidence-based standards, these statistics should validate what many have experienced firsthand: most GenAI implementations don't deliver on their promises.
The Demo-to-Production Chasm
The most revealing statistic may be this: 88% of AI proof-of-concepts never reach production [5]. This isn't about organizations failing to recognize AI's potential in controlled demonstrations. The technology works nicely in demos. Models generate impressively fluent text, summarize documents, and answer questions with apparent sophistication. The failure occurs in the transition from prototype to operational system, what I call the "demo-to-production gap." Which is NOT something I am immune to either. But building so many demos and prototypes, observing their behaviors under different conditions helped me make sense of the gap between the immense potential of GenAI models and real-world use case success rates.
This gap reveals something fundamental: the problem isn't the AI model itself. If model capability were the limiting factor, we'd see demos fail. Instead, we see demos succeed and production systems fail.
What Actually Causes Failure? Not What You Might Think
Across every major research study, the root causes of GenAI failure cluster around system design, not model limitations. According to Informatica's 2025 CDO Insights survey, 43% of organizations cite data quality and readiness as the primary obstacle to GenAI success, while another 43% cite lack of technical maturity in their infrastructure [3]. Only 7% of enterprises have fully embedded AI governance programs with continuous monitoring [3]. The RAND study is explicit: AI projects fail due to "systematic issues in leadership, infrastructure, and understanding limitations, not technology gaps" [4].
The IBM Watson Health deployment at MD Anderson Cancer Center provides a cautionary case study. The $62 million project was terminated in 2016, not because Watson's natural language processing was inadequate, but because of poor clinical workflow integration, inability to access patient data after an EHR system migration, and failure to interpret clinical context effectively [6,7]. The AI model could parse text; the system couldn't deliver the right text at the right time in the right format to the right users.
This distinction matters profoundly. If the problem were model capability, the solution would be waiting for better models. But if the problem is system design (i.e. how we select, structure, and deliver information to models, how we integrate AI into workflows, how we govern data quality) then the solution is engineering discipline, not technological advancement.
The Path Forward Starts With Honest Assessment
Professional skepticism toward GenAI is empirically justified. The 95% failure rate is real. The billions in wasted investment are documented. The pattern of promising demos followed by disappointing production systems is consistent across industries.
But here's what the data also shows: the 5% that succeed aren't using fundamentally different AI models. They're engineering their systems differently. They're addressing data quality before deployment, not after. They're designing governance structures from day one. They're treating “context”, the information environment surrounding the model, as the primary determinant of success.
Understanding why 95% fail is the first step toward joining the 5% that succeed. The answer lies not in the models themselves, but in the systematic discipline of context engineering, a framework we'll explore below.
From Prompt Engineering to Context Engineering: A Paradigm Shift
The GenAI systems that fail aren't using worse models than the ones that succeed. They're engineering their systems differently. Specifically, they're focusing on the wrong layer of the architecture.
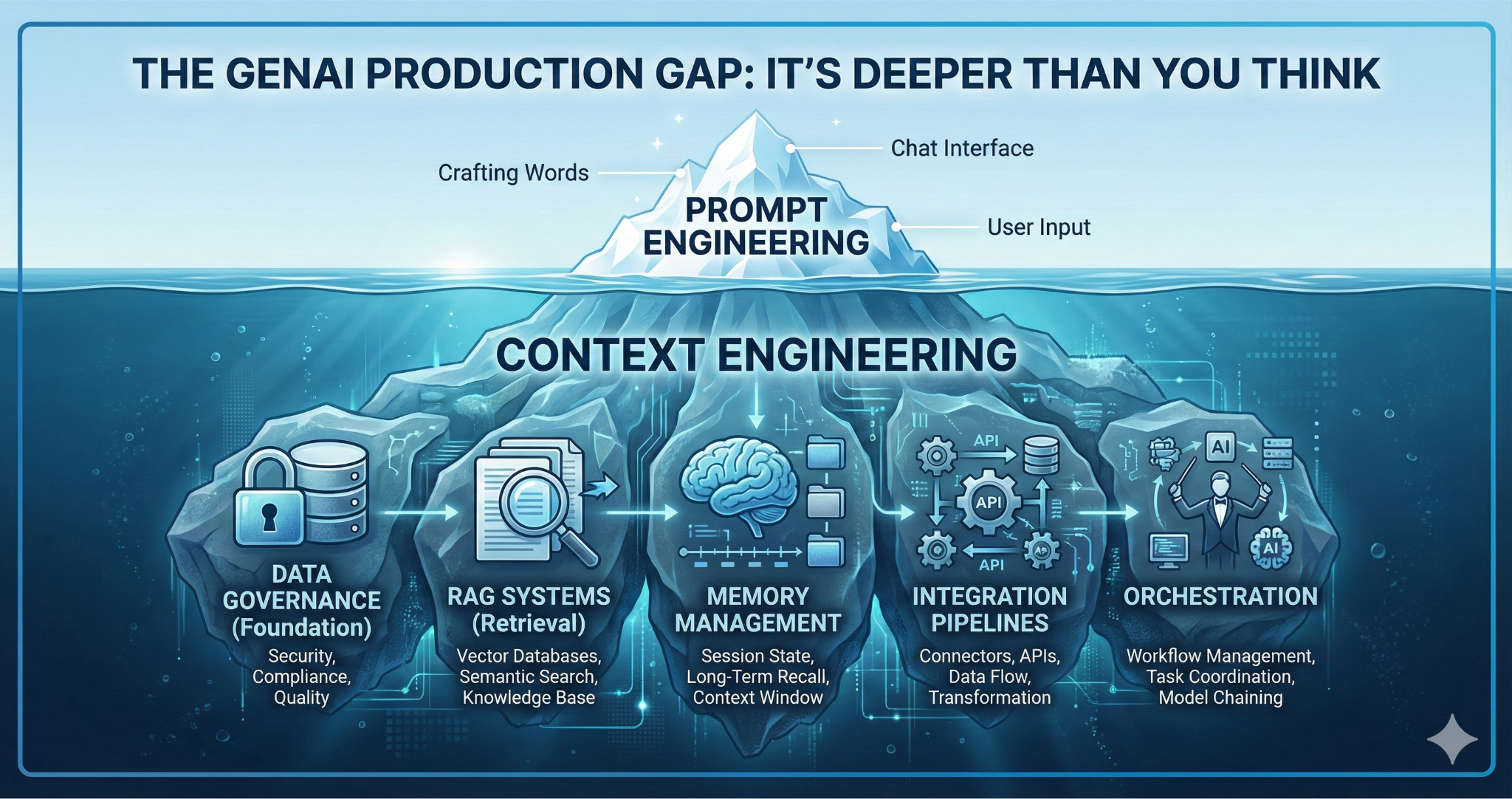
Most organizations approach GenAI through prompt engineering: crafting individual instructions, refining phrasing, experimenting with different ways to ask questions. This approach treats the model as a conversational interface where success depends on finding the right words. It's an iterative, trial-and-error craft, valuable for specific interactions but insufficient for production systems.
Context engineering represents a fundamental architectural shift. Where prompt engineering focuses on what you say to the model, context engineering focuses on what the model has access to, the entire information environment during inference. This distinction isn't semantic. It's the difference between optimizing a user interface and designing the data systems, retrieval mechanisms, memory structures, and governance frameworks that determine whether accurate, relevant information reaches the model at all.
Industry Leaders Formalize the Transition
In mid-2025, this shift gained formal recognition from major industry figures. Andrej Karpathy, former director of AI at Tesla and researcher at OpenAI, articulated context engineering as "the delicate art and science of filling the context window with just the right information for the next step" [8]. He positioned it explicitly as a successor discipline to prompt engineering, moving from individual prompt crafting to what he calls "industrial-strength LLM application work."
Tobi Lütke, CEO of Shopify, framed it more directly: context engineering is "the art of providing all the context for the task to be plausibly solvable by the LLM" [9]. His emphasis shifts focus from prompt cleverness to information quality and completeness. For enterprise applications, this reframing is critical: it means success depends primarily on whether the right data exists, is accessible, and reaches the model in usable form, not whether someone wrote an elegant instruction.
Anthropic formalized the concept in its September 2025 engineering blog, defining context engineering as "the natural progression of prompt engineering" and more precisely as "strategies for curating and maintaining the optimal set of tokens (information) during LLM inference, including all information that may land there outside of prompts" [6]. That final phrase, "outside of prompts", is crucial. It acknowledges that production GenAI systems involve far more than what users type into a chat interface.
What Context Engineering Actually Encompasses
Context engineering addresses six interdependent components that together determine system performance:
- Retrieval systems (often called RAG - Retrieval-Augmented Generation) that connect models to external knowledge bases, ensuring access to current, domain-specific information beyond static training data.
- System prompts that establish persistent application behavior, role definitions, and safety constraints across all interactions, processed at higher priority than user inputs.
- Data sources and quality that determine whether accurate, relevant information exists and is accessible when needed, the foundation that all other components depend on.
- Memory management that preserves conversation history, learned patterns, and feedback across sessions, enabling adaptive behavior over time.
- Tools and function calling that allow models to interact with APIs, databases, and operational systems, moving beyond text generation to real-world actions.
- Governance structures that ensure data lineage, compliance, continuous monitoring, and quality controls, particularly critical in regulated domains like healthcare.
When you view GenAI through this framework, the 88% proof-of-concept failure rate makes sense. Demos succeed because they operate in controlled environments with curated data, simplified retrieval, and no integration requirements. Production systems fail because they require systematic design across all six components simultaneously. A brilliant prompt cannot compensate for poor retrieval quality, inadequate data governance, or missing memory systems.
Why This Shift Matters for Skeptical Professionals
For health economists and outcomes research professionals, the transition from prompt engineering to context engineering is particularly relevant. Our professional standards emphasize data quality, methodological rigor, evidence validation, and reproducibility, precisely the concerns that context engineering addresses and prompt engineering ignores.
Context engineering reframes GenAI as an information architecture problem, not a conversation optimization problem. It requires the same systematic thinking applied to database design, ETL pipelines, and data governance. It demands version control, testing protocols, and continuous monitoring which are standard engineering practices.
The Stanford research finding that 78% of organizations use AI while only 21% redesigned workflows to integrate it [6] reveals the gap. Organizations treat GenAI as a tool to bolt onto existing processes rather than a system requiring architectural changes to data access, retrieval mechanisms, and governance. This is precisely why demos work and production systems don't.
Context engineering provides a diagnostic framework. When GenAI systems fail, you can identify which component is broken: Is retrieval bringing back irrelevant information? Are system prompts inadequately structured? Is data quality compromised? Is memory failing to preserve important context? This specificity transforms GenAI from an unpredictable black box into an engineerable system with measurable failure modes and addressable root causes.
The industry leaders who formalized this shift aren't selling hope. They're describing the technical reality that separates successful implementations from failed ones. The question isn't whether to adopt context engineering. It's whether to continue approaching GenAI through prompt crafting alone and accept 95% failure rates, or to adopt the systematic engineering discipline that the successful 5% are already using.
The Six Pillars of Context Engineering: A Technical Framework
Understanding why GenAI systems fail requires moving beyond general concepts to specific technical components. Weaviate's Six Pillars framework provides the systematic architecture that distinguishes production-grade implementations from failed prototypes [10]. These six interdependent components:
- Agents,
- Query Augmentation,
- Retrieval (RAG),
- Prompting,
- Memory, and
- Tools
which together determine whether a GenAI system can access, process, and act on information reliably.
The critical insight: these components are interdependent, not additive. Excellence in three pillars cannot compensate for failure in one. This interdependence explains why partial implementations (e.g.organizations that implement sophisticated retrieval but neglect memory management, or that invest heavily in prompting while ignoring data quality) consistently fail. The 88% proof-of-concept failure rate reflects systems engineered at the component level but not architected at the system level.

The Six Components and Their Failure Modes
Retrieval (RAG) connects LLMs to external knowledge bases, solving the fundamental problem that models only "know" what was in their training data. Research consistently identifies retrieval quality as the highest-impact component [10,11]. When retrieval fails, everything downstream fails, no amount of prompt sophistication can extract accurate answers from irrelevant or contradictory source material.
NB-Data's analysis of 23 documented RAG pitfalls reveals specific failure modes: vague queries with unclear referents ("What went wrong there last time?") cause semantic drift, bringing back information about the wrong "there" or "last time" [11]. Poor embedding quality leads to semantically irrelevant matches, documents that share keywords but not meaning. Inadequate ranking puts the most relevant information outside the model's attention span. Contradictory retrieved content confuses models, leading to hedged or incorrect responses.
Query Augmentation refines user input before retrieval occurs. Raw user queries are often ambiguous, context-dependent, or poorly specified. Query augmentation techniques, expanding abbreviations, adding domain context, disambiguating references, transform vague inputs into precise retrieval targets. Without this component, even perfect retrieval systems fail because they're searching for the wrong information. A health economics query about "outcomes" might mean clinical outcomes, economic outcomes, patient-reported outcomes, or quality-adjusted outcomes, query augmentation resolves this ambiguity before retrieval begins.
Prompting Frameworks structure how models process retrieved information. This goes beyond crafting individual instructions to applying systematic reasoning patterns: Chain-of-Thought prompting guides step-by-step logical reasoning; ReAct (Reasoning + Acting) enables models to interleave information gathering with reasoning; Tree of Thoughts explores multiple reasoning paths before committing to conclusions. Failure mode: models that receive perfect context but lack structured prompting often ignore retrieved evidence entirely, generating plausible-sounding responses untethered from provided facts [11].
Agents orchestrate which information to retrieve and when. Rather than static, one-time retrieval, agents make dynamic decisions: Does this query require external information or can it be answered from memory? Should retrieval occur before or after initial reasoning? Are multiple retrieval passes needed to resolve ambiguity? Agent failures manifest as retrieval at the wrong time (retrieving information the model already has, or failing to retrieve when critical gaps exist) or retrieval of the wrong scope (too narrow, missing critical context; too broad, introducing noise).
Memory preserves conversation history, learned patterns, and feedback across interactions. Without memory, systems cannot adapt, they make the same mistakes repeatedly, fail to learn user preferences, and lose context across conversation turns. The MIT finding that 95% of GenAI pilots fail to deliver measurable return reflects, in part, the "learning gap": most systems are stateless, processing each query as if it's the first, never improving based on feedback [1]. Memory systems must distinguish between session-specific context (relevant only to current conversation) and persistent learning (patterns that should inform future interactions across all users).
- Tools and Function Calling enable models to take real-world actions, querying databases, invoking APIs, executing calculations, triggering workflows. Without tools, GenAI remains purely generative: it can draft a message but can't send it; suggest a database query but can't execute it; recommend an action but can't implement it. For enterprise applications, this limitation is fatal. Health economics applications require integration with clinical databases, cost calculators, literature databases, and reporting systems, capabilities that require tool access, not just text generation.
Why System Architecture Trumps Component Quality
Consider a scenario: Your retrieval system achieves 95% accuracy, it consistently returns the right information. Your prompts are sophisticated, incorporating Chain-of-Thought reasoning. But your query augmentation is poor, so 40% of user queries are misinterpreted before they reach retrieval. Effective system accuracy is 95% × 60% = 57%. Or your retrieval is perfect, but your memory system fails to preserve critical context across conversation turns, forcing users to re-explain background in every interaction. Cognitive load increases, adoption falls, and the project is deemed a failure despite technically excellent components.
Research on context performance demonstrates this compounding effect empirically. ArXiv studies testing five models across multiple task types found that even with perfect retrieval, 100% exact match of required evidence, performance degrades substantially when other components (prompt structure, token management, memory) are inadequate [11]. The Chroma research on context rot shows similar patterns: models with access to correct information still fail when that information is embedded in poorly structured, overly long, or internally contradictory contexts [12].
This interdependence explains the demo-to-production gap. Demos typically optimize one or two components, impressive retrieval demonstrations or clever prompting examples. Production systems require all six components functioning simultaneously under variable conditions: ambiguous user queries, incomplete data, contradictory sources, evolving requirements, integration constraints. A chain is only as strong as its weakest link; a context engineering system is only as reliable as its least-developed pillar.
Relative Importance: Where to Focus First
While all six components are necessary, research consistently identifies a hierarchy of impact. RAG and retrieval quality rank highest. If the right information doesn't reach the model, nothing else matters [10,11]. Organizations should prioritize data quality, semantic search effectiveness, and retrieval validation before investing heavily in other components.
Prompt and instruction clarity rank second. Even with perfect retrieval, models must be instructed to use provided context, cite sources, acknowledge uncertainty when information is incomplete, and follow domain-specific reasoning patterns. Token optimization emerges as third-tier priority. Not because it's unimportant, but because it's only meaningful after you've ensured the right information is being retrieved and properly processed.
For skeptical professionals evaluating GenAI implementations, this framework provides diagnostic power. When a system fails, you can ask: Which pillar is broken? Is retrieval bringing back irrelevant information (Pillar 3 failure)? Are queries too vague to target correct information (Pillar 2 failure)? Is the system failing to learn from corrections (Pillar 5 failure)? Is the prompt structure inadequate to guide reasoning (Pillar 4 failure)?
This specificity transforms GenAI from an opaque system that "sometimes works and sometimes doesn't" into an engineerable architecture with identifiable failure modes, measurable performance at each component, and systematic paths to improvement. That transformation, from craft to engineering, is what separates the 5% that succeed from the 95% that fail.
Context Quality Over Quantity: The Science of What to Include
If more information were always better, the industry's largest context windows would solve the GenAI reliability problem. They don't. Models now support 200,000 tokens, approximately 150,000 words, or roughly 400 pages of text, yet performance failures persist [12]. The reason challenges a fundamental assumption: more context doesn't improve reliability. In many cases, it actively degrades it.
This phenomenon, termed "context rot" by researchers at Chroma, reveals a critical constraint that context engineering must address: LLMs have finite attention budgets, and performance degrades systematically as input length increases, even when retrieval is perfect [12].
The Context Rot Phenomenon: Empirical Evidence
Chroma's research tested 18 state-of-the-art models, including GPT-4, Claude 3.5 Sonnet, and Gemini 2.5 Flash, on a deceptively simple task: locating and repeating a specific word embedded in increasingly long contexts. The task requires no reasoning, no domain knowledge, no ambiguity resolution, just finding information explicitly provided. Models with 128K token context windows should handle this trivially.
They don't. Performance drops from near 100% accuracy with short contexts to 0% with longer ones. Models produce unrelated words, hallucinate answers, or provide no answer at all, despite the correct information being present in the input [12]. Critically, this degradation occurs well before models approach their stated token limits, and it affects even trivial instruction-following tasks.
ArXiv research provides systematic confirmation across five models (including Llama-3.1, Mistral, and others) on math problems, question answering, and code generation. Even with perfect retrieval, performance degrades substantially as context length increases. Llama-3.1-8B, for instance, shows 50 percentage point performance drops on mathematical tasks when context extends from zero to 30,000 tokens [11]. The model has access to the right answer; it simply cannot reliably locate and utilize it within longer contexts.
Token Economics and Attention Budgets
Understanding why this occurs requires recognizing that LLMs process information through attention mechanisms with finite capacity. Each additional token doesn't just add information, but it consumes computational resources from a fixed budget. As contexts grow, the model must distribute attention across more tokens, diluting focus on any individual piece of information.
Token economics compound this constraint. One token approximates 0.75 words in English; a 128K token context window represents 96,000-250,000 words depending on formatting [12]. For a health economics application analyzing clinical trial data, cost-effectiveness models, and patient outcomes literature, reaching these limits is trivial. But filling the context window isn't free, it's expensive in both computational cost and reliability degradation.
At enterprise scale, token waste becomes financially material. Consider: 1,000 unnecessary tokens per query, multiplied by 10 million daily queries, at $0.002 per 1,000 tokens equals $20,000 daily, or $7.3 million annually [12]. More critically, those wasted tokens aren't just expensive; they're actively degrading model performance by consuming attention budget on irrelevant information.
The strategic implication: context engineering must optimize for sufficiency, not comprehensiveness. The goal isn't providing all potentially relevant information, it's providing precisely the information needed while excluding everything else. This reframing transforms context engineering from a maximization problem (how much can we include?) to an optimization problem (what's the minimum sufficient context?).
Quality Failures Degrade More Than Information Absence
Research demonstrates that quality failures, contradictory information, vague queries, irrelevant context, cause more performance degradation than missing information [11]. NB-Data's analysis of RAG system failures documents this pattern across 23 documented pitfalls: models receiving contradictory retrieved context produce hedged, uncertain, or incorrect responses more often than models receiving incomplete but consistent information [11].
Vague queries with unclear referents illustrate the problem. A query like "What went wrong there last time?" contains three ambiguous references: "what" (which aspect?), "there" (which location or context?), and "last time" (which timepoint?). Without query augmentation, retrieval systems must guess at referents, often bringing back information about the wrong "there" or "last time." The resulting context may be accurate for a different question but irrelevant to the actual intent, worse than no information because it consumes attention budget while providing no value [11].
Contradictory retrieved information creates a similar failure mode. If retrieval returns one document stating that a clinical trial showed statistically significant improvement and another stating it didn't, the model faces an impossible task: which source is authoritative? Without metadata about document dates, quality, or hierarchy, models typically hedge ("results are mixed") or favor the most confidently stated claim, regardless of accuracy. For health economics applications where evidence quality directly determines regulatory and reimbursement decisions, this failure mode is unacceptable.
Irrelevant context, information that's semantically related but functionally useless for the task, may be the most insidious quality failure. Research shows that seemingly relevant but ultimately unhelpful information degrades performance more than random text [12]. A query about cost-effectiveness ratios might retrieve literature discussing cost measurement methodologies, effectiveness measurement challenges, and ratio calculation techniques, all semantically related, none directly answering the question. This "near miss" retrieval fills the context window with distractors that are harder for the model to dismiss than obviously irrelevant content.

Implications for Context Engineering Practice
These findings mandate specific practices. First, implement RAG for just-in-time retrieval rather than preloading comprehensive information. A legal firm reduced token usage from 15,000 to 4,500 tokens per contract query by retrieving only relevant clauses instead of full 50-page contracts, achieving both cost reduction and accuracy improvement [12]. The principle applies directly to health economics: retrieve the specific study results, cost data, or clinical parameters needed for the current analysis rather than providing entire literature reviews.
Second, invest heavily in query augmentation before retrieval. Disambiguate references, expand domain-specific abbreviations, add temporal and contextual qualifiers. A vague query about "outcomes in the recent study" should be augmented to specify which study, which outcome measures, and which timepoints before retrieval begins. This front-end investment in query quality prevents downstream context rot.
Third, validate retrieved information for contradictions before providing it to the model. If multiple sources conflict, context engineering systems must either resolve the contradiction (by prioritizing more recent data, higher-quality sources, or more specific evidence) or explicitly surface the contradiction rather than hoping the model navigates it correctly.
Fourth, monitor for context rot symptoms: degrading performance despite apparently successful retrieval, increased hedging or uncertainty in model outputs, failure to cite specific retrieved sources, and generic responses when specific answers should be possible. These patterns indicate that information is reaching the model but not being effectively utilized, a hallmark of context length degradation.
The overarching principle: quality and strategic selection matter more than quantity. The 5% of GenAI implementations that succeed aren't providing more information. They're providing better information, more precisely targeted, with quality validation that prevents the contradictions, vagueness, and irrelevance that cause context rot. For skeptical professionals accustomed to evidence-based standards, this principle should be familiar: it's the same discipline applied to systematic literature reviews, where inclusion criteria, quality assessment, and synthesis methodology determine whether results are reliable or misleading.
Context engineering applies that same rigor to information architecture, not as an afterthought, but as the foundation of reliable GenAI systems.
From Theory to Practice: Implementing Context Engineering Systematically
Understanding the six pillars and the science of context quality is necessary but insufficient. The question skeptical professionals should ask isn't whether context engineering makes theoretical sense, it's whether organizations can implement it reliably in production environments. The answer depends entirely on whether you treat GenAI as experimental technology requiring craft expertise or as engineerable infrastructure requiring systematic discipline.
The 5% that succeed do the latter. They approach context engineering like software engineering: with version control, continuous integration, security protocols, and continuous monitoring. The 95% that fail treat GenAI as a prototype that can be promoted to production without fundamental architectural changes.
Start Minimal, Test Rigorously, Add Complexity Incrementally
Anthropic's implementation framework begins with a principle that contradicts most organizations' instincts: start with the absolute minimum viable system, not a comprehensive implementation [6]. This counterintuitive approach reflects a critical insight: you cannot diagnose failure causes in complex systems. If you build a context engineering system with sophisticated retrieval, elaborate prompts, multi-stage query augmentation, and extensive memory management simultaneously, and it fails, which component is broken?
The framework mandates [6]:
- Begin with minimal system prompts: a clear role definition and basic output format, nothing more;
- Test with the best available models first to establish performance ceiling
- Add examples (few-shot prompting) only after baseline performance is documented
- Implement retrieval only after confirming that prompt structure enables models to use provided context effectively
- Add memory and tool integration only after validating that single-turn interactions work reliably
This staged approach enables systematic diagnosis. If performance is inadequate at the minimal baseline, the problem is prompt structure or model capability, not retrieval quality, not memory management, not query augmentation. Only after establishing baseline competence should you add complexity. Research demonstrates that few-shot prompting with 3-5 diverse, canonical examples yields up to 6x higher accuracy compared to zero-shot baselines, and often rivals fine-tuned models [6]. But adding examples before verifying prompt structure simply obscures whether improvements (or failures) stem from better instructions or better examples.
For health economics applications, this means resisting the temptation to immediately connect your GenAI system to comprehensive literature databases, cost-effectiveness registries, and clinical trial repositories. Start with a curated sample of 10-20 documents representing the range of queries you expect. Test whether your system can reliably retrieve and cite specific information from that limited corpus. Only after confirming retrieval reliability should you scale to comprehensive databases.
Addressing the Learning Gap: Feedback Loops and Adaptive Memory
The MIT research identifying 95% failure rates specifically cites the "learning gap" as root cause: most GenAI systems don't retain feedback, adapt to context, or improve over time [1]. They process queries as isolated transactions, repeating mistakes indefinitely because they have no mechanism to learn from corrections.
Stanford's Agentic Context Engineering (ACE) framework addresses this systematically through a three-stage cycle [6]:
- Generator: produces responses,
- Reflector: extracts lessons from interactions, and
- Curator integrates insights into structured context updates.
Rather than treating context as static prompt text, ACE maintains an "evolving playbook": structured knowledge that accumulates successful strategies, domain-specific patterns, and corrections to common errors.
Consider a health economics application processing cost-effectiveness queries. Initial deployments might retrieve studies using narrow search criteria, missing relevant international evidence. A traditional system repeats this limitation indefinitely. An ACE-framework system captures feedback when users manually supplement results with additional studies, extracts the pattern (queries mentioning specific conditions should include international registries), and integrates this lesson into query augmentation rules. Future queries benefit from prior feedback without requiring users to repeatedly provide the same corrections.
Implementation requires architectural decisions about memory scope and persistence. Session-specific memory (relevant only to current conversation) must be distinguished from persistent learning (patterns that should inform all future interactions). User-specific preferences (preferred outcome measures, citation formats, cost perspectives) must be separated from system-wide improvements (universal query augmentation rules, validated retrieval strategies).
Feedback mechanisms must capture signals from multiple sources: explicit user corrections, implicit signals (queries reformulated immediately after initial response suggests inadequacy), performance metrics (response time, retrieval relevance scores, citation accuracy), and domain expert review. The Deloitte finding that 74% of organizations with advanced GenAI initiatives meet or exceed ROI expectations reflects implementations featuring systematic feedback integration, not just technically sophisticated models [6].
Governance as Foundation, Not Afterthought
The 7% of organizations with embedded governance aren't adding bureaucracy. They're implementing the prerequisites for reliable production systems [3]. Context engineering governance requires cross-functional teams spanning IT (infrastructure and security), compliance (regulatory requirements and data privacy), legal (intellectual property and liability), and business units (domain expertise and success metrics).
Data governance ensures quality, lineage, and compliance. For health economics applications, this means validating that retrieved cost data is current, that clinical outcomes are sourced from peer-reviewed publications or registered trials, that patient-level data meets privacy requirements, and that all information can be traced to authoritative sources. The 43% of organizations citing data quality as the primary GenAI obstacle aren't describing a technical problem, they're identifying missing governance [3].
Continuous performance monitoring with clear KPIs distinguishes production systems from prototypes. Metrics must address multiple dimensions: retrieval relevance (are retrieved documents semantically appropriate?), citation accuracy (are generated citations verifiable?), response latency (are systems performant at scale?), cost efficiency (is token usage optimized?), and user satisfaction (are outputs meeting needs?). The 89% of enterprise leaders citing ROI as the top AI success metric while less than 50% feel confident measuring it reflects this governance gap [6].
Version control and change management extend beyond prompts to all context components: retrieval algorithms, query augmentation rules, memory retention policies, tool integrations, and security controls. When performance degrades, organizations with comprehensive change tracking can identify which component modification caused the regression. Organizations without it resort to trial-and-error debugging.
Risk assessment and mitigation protocols matter particularly in high-stakes domains. Healthcare applications require failure mode analysis: what happens if retrieval returns outdated clinical guidelines? If citation generation hallucinates nonexistent studies? If cost calculations use superseded pricing data? Governance frameworks mandate detection mechanisms, fallback procedures, and human oversight for high-risk decisions.
The 95% to 5% Transition: Systematic Implementation Differentiators
Research consistently identifies what separates successful implementations from failures. Early governance integration during system design, not retrofit after deployment. Systematic evaluation from conception, not just pre-deployment testing. Workflow redesign to integrate AI as infrastructure, not bolting it onto existing processes. Data preparation and quality validation as prerequisites, not afterthought. Continuous monitoring enabling adaptation, not one-time deployment. Clear business metrics aligned with organizational objectives before pilots launch [1,6].
The 78% of organizations using AI while only 21% redesigned workflows exemplifies the problem [6]. Adding GenAI to existing processes without addressing how information flows, how decisions are validated, or how feedback is captured creates the demo-to-production gap. Successful implementations recognize that context engineering requires rethinking information architecture, not just adopting new tools.
For skeptical professionals who have experienced GenAI disappointments, this framework offers both vindication and path forward. Your skepticism was justified, most implementations lack the systematic discipline that production systems require. But the solution isn't abandoning GenAI. It's engineering it properly: with the version control, testing protocols, governance structures, and continuous improvement mechanisms that separate reliable infrastructure from experimental prototypes.
The 5% success rate isn't a ceiling, it's proof of concept. Context engineering works when implemented systematically. The opportunity is bringing the remaining 95% up to production-grade engineering standards.
Conclusion: A Path Forward for Evidence-Driven Professionals
If you began this white paper skeptical about GenAI, your instinct was empirically sound. The 95% failure rate is real, the billions in wasted investment are documented, and the pattern of promising demonstrations followed by disappointing production deployments is consistent across industries [1]. For health economists and outcomes research professionals accustomed to evidence-based standards, this track record justifies caution.
But the diagnostic framework presented here suggests a different conclusion than abandoning GenAI entirely: the problem isn't the technology, it's how we're engineering it.
Reframing GenAI Through Engineering Discipline
Context engineering fundamentally transforms GenAI from unpredictable "black box" to engineerable system. Where prior implementations treated AI outputs as mysterious emergent behavior dependent on model quality alone, context engineering provides a structured architecture with measurable inputs at each component: retrieval quality, query precision, prompt structure, memory management, tool integration, and governance controls.
This reframing aligns directly with evidence-based professional standards. The Weaviate Six Pillars framework isn't aspirational, it's diagnostic [10]. When a system fails, you can identify which component is broken: Is retrieval bringing back irrelevant information? Are queries too vague to target correct data? Is the prompt structure inadequate? Is memory failing to preserve critical context? This specificity enables systematic improvement through the same iterative testing and refinement applied to clinical protocols or economic models.
For health economics professionals, the parallel is direct. Evidence-based medicine requires validated data sources, systematic literature review methodology, transparent analytical approaches, and continuous quality monitoring. Context engineering applies identical discipline to AI systems: validated data sources (through retrieval quality assurance), systematic information selection (through query augmentation and RAG optimization), transparent processing (through prompt structure and source attribution), and continuous monitoring (through governance frameworks and performance metrics). The methodological standards you already apply to research translate directly to context engineering requirements.
The 5% Success Pattern: Common Characteristics
Research across MIT, Deloitte, and industry analyses reveals consistent patterns distinguishing successful implementations from failures [1,6]. These organizations don't use fundamentally different models. They engineer their systems differently from conception.
Systematic context design precedes deployment. Successful implementations begin with information architecture: what data exists, how it's accessed, what quality controls ensure accuracy, and how retrieval is validated. They test with minimal viable systems before adding complexity. They establish baseline performance before scaling. The Stanford ACE framework's approach, treating context as an "evolving playbook" rather than static prompts, reflects this discipline [6]. Systems improve through structured feedback integration, not trial-and-error prompt tweaking.
Data governance is prerequisite, not afterthought. The 43% of organizations citing data quality as the primary GenAI obstacle aren't describing technical limitations, they're identifying missing governance foundations [3]. Successful implementations validate data lineage, ensure information currency, and implement quality controls before models ever access data. For healthcare applications, this parallels clinical data governance: the same validation protocols ensuring research integrity apply to context engineering systems.
Workflow integration is designed simultaneously with AI capabilities. The finding that 78% of organizations use AI while only 21% redesigned workflows explains the demo-to-production gap [6]. Successful implementations recognize that GenAI isn't always a tool to bolt onto existing processes. It requires rethinking information flow, decision validation, and feedback capture. They treat context engineering as infrastructure engineering, not feature addition.
Continuous monitoring enables adaptation. The "learning gap" MIT identified, systems failing because they don't improve over time, reflects missing feedback loops [1]. Successful implementations capture corrections, extract patterns from user behavior, and integrate lessons into system design. They monitor retrieval relevance, citation accuracy, response latency, and user satisfaction as operational metrics, not post-deployment audits.
Deloitte's finding that 74% of organizations with advanced GenAI initiatives meet or exceed ROI expectations when implementing these characteristics demonstrates that success is replicable, not accidental [6]. The successful 5% aren't lucky, they're systematic.
Professional Skepticism as Strategic Asset
For professionals who have experienced GenAI disappointments, context engineering offers vindication: your skepticism was justified, but the diagnosis requires updating. The failures you witnessed stemmed from poor system design, inadequate data preparation, missing governance, insufficient workflow integration, not inherent AI limitations. The IBM Watson Health failure at MD Anderson exemplified this: the model wasn't the problem; context management, data access, and workflow integration were [7,9].
This distinction creates opportunity. Professional skepticism, the instinct to demand evidence, question claims, and validate before trusting, becomes an asset when channeled into context engineering requirements. The questions skeptical professionals naturally ask align perfectly with context engineering discipline:
How do we validate that retrieved information is accurate and current? Through data governance, source validation, and retrieval quality metrics.
How do we ensure AI outputs are grounded in evidence, not hallucinated? Through RAG architectures that ground responses in verified sources, citation requirements, and confidence scoring.
How do we prevent models from using outdated or contradictory information? Through query augmentation that specifies temporal requirements, retrieval ranking that prioritizes currency and authority, and contradiction detection in retrieved context.
How do we monitor whether systems are performing reliably at scale? Through continuous performance metrics, user feedback integration, and governance frameworks with defined KPIs.
These aren't obstacles to adoption. They're requirements for production-grade systems. Organizations treating them as checklists to bypass will join the 95% that fail. Organizations treating them as engineering fundamentals will join the 5% that succeed.
The Path Forward: From 5% to Standard Practice
The current 5% success rate isn't a ceiling, it's proof that context engineering works when implemented systematically. The path forward isn't waiting for better models. It's bringing implementation discipline up to production-grade engineering standards that the successful minority already practices.
For skeptical professionals, this means re-engaging with GenAI, not abandoning it, but with different criteria. Evaluate implementations not by demonstration quality but by evidence of context engineering discipline: Does the proposal address data governance? Is retrieval quality validated? Are workflows being redesigned, not just augmented? Is continuous monitoring planned from day one? Are prompts version-controlled and deployed through tested pipelines?
Context engineering has transitioned from emerging practice to recognized discipline. Industry leaders have published frameworks, not vague principles. Implementation patterns are standardizing. Best practices are codifying. The field is maturing from experimental technology requiring craft expertise to engineerable infrastructure requiring systematic discipline.
For health economists and outcomes research professionals, this maturation matters. Your domain expertise in evidence evaluation, methodological rigor, and data quality isn't tangential to GenAI success, it's foundational to context engineering. The same critical thinking that makes you skeptical about unvalidated AI claims makes you ideally positioned to implement context engineering properly.
The 95% failure rate reflects organizations approaching GenAI as magic requiring faith. The 5% success rate reflects organizations approaching it as engineering requiring discipline. Your choice determines which trajectory you follow and whether GenAI becomes another disappointing technology cycle or a genuine capability enhancement grounded in the same evidence-based standards you already apply to every other aspect of your professional work.
References
[1] MIT NANDA Initiative. (2025). The GenAI Divide: State of AI in Business 2025. Link
[2] NTT DATA Group. (2024). Between 70–85% of GenAI Deployment Efforts Failing to Meet Desired ROI. Link
[3] Gartner. (2025). Generative AI Project Abandonment and Deployment Failure Rates. Link
[4] RAND Corporation. (2024). The Root Causes of Failure for Artificial Intelligence Projects and How They Can Succeed: Avoiding the Anti-Patterns of AI. Link
[5] IDC (in partnership with Lenovo). (2025). AI Proof-of-Concept Failure Analysis. Link
[6] Anthropic. (2025, September 29). Effective Context Engineering for AI Agents. Engineering Blog. Link
[7] IEEE Spectrum. (2016). How IBM Watson Overpromised and Underdelivered on AI Health Care. Link
[8] Karpathy, A. (2025). Context Engineering for AI Applications. Link
[9] Lütke, T. (2025). Context Engineering and AI System Design. Link
[10] Weaviate. (2025). Context Engineering for AI Agents: Six Pillars Framework. Link
[11] NB-Data. (2024). 23 RAG Pitfalls and How to Fix Them. Link
[12] Chroma. (2025). Context Rot: How Increasing Input Tokens Impacts LLM Performance. Link
[13] Hong, K., Chroma Research. (2025). Context Rot and Long-Context LLM Performance Degradation.
Download the Full Paper
Get the PDF version with complete references for offline reading and sharing with your team.
Developed by Aide Solutions LLC. This white paper was prepared with the support of generative artificial intelligence tools. The author reviewed, edited, and takes full responsibility for the content and conclusions presented. Full references are available in the PDF version.