Executive Summary
The current business discourse surrounding Large Language Models (LLMs) is polarized, trapping leaders between evangelistic hype and skeptical fear. This false binary leads to either reckless adoption or paralyzing inaction, with both camps misunderstanding the technology's fundamental nature. The root of this problem is the "Magic Box Fallacy"—the belief that an LLM is a standalone, autonomous solution capable of solving complex problems in isolation. Consequently, enterprise AI initiatives suffer from staggering failure rates when these unrealistic expectations are not met.
This white paper argues that the path to successful LLM implementation lies in discarding the magic box mindset and adopting a holistic, systems-based approach. Using the analogy of a Formula 1 racing team, I reframe the LLM as a powerful engine—a critical component, but one that cannot win a race on its own. To succeed, this engine must be integrated into a complete, high-performance system.
I introduce a five-part framework for building this system:
- AI Processing (The Engine): The LLM itself, used for probabilistic tasks like drafting and summarization.
- Traditional Coding (The Chassis): Deterministic code that provides structure, logic, and reliability.
- Expert Oversight (The Driver): The non-negotiable human-in-the-loop providing judgment and strategic context.
- Curated Context (The Race Strategy): The discipline of prompt engineering and grounding the LLM with relevant, high-quality data.
- Tool Connectivity (The Pit Crew): APIs and integrations that connect the system to real-time data and external tools.
Success is not measured by the standalone performance of the AI, but by the enhanced performance of the entire human-led workflow. By shifting metrics from "AI accuracy" to "workflow enhancement"—such as time savings, error rate reduction, and expert time reallocation—organizations can unlock genuine value. We conclude with practical guidelines for implementation, emphasizing the importance of starting with bounded use cases, architecting for modularity to future-proof the investment, and cultivating user competency as the ultimate competitive advantage. The goal is not merely to acquire technology, but to build a lasting organizational capability.
The Polarization Problem: Why Current LLM Discourse Misses the Mark
The current business conversation surrounding Large Language Models (LLMs) and Generative AI resembles a ringside commentary on a heavyweight fight more than a strategic discussion. In one corner, we have the evangelists proclaiming this technology as a silver bullet capable of solving any problem, revolutionizing industries overnight, and delivering unprecedented productivity gains with plug-and-play simplicity. In the opposite corner stand the skeptics, pointing to high-profile failures, factual inaccuracies ("hallucinations"), and alarming project failure rates as definitive proof that the technology is an overhyped, unreliable, and ultimately dangerous distraction.
After observing and guiding numerous implementation efforts, I can say with confidence that both sides are missing the point. This polarized, all-or-nothing discourse creates a false binary that forces leaders into one of two unproductive camps: reckless adoption or paralyzing inaction. The truth is that LLMs are neither a miracle cure nor a categorical failure. They are exceptionally powerful tools—akin to a revolutionary new engine in Formula 1 racing. But an engine, no matter how powerful, does not win a championship on its own. It requires a meticulously engineered chassis, a world-class driver, a flawless pit crew, and a brilliant race strategy to even finish a race, let alone win one.
The widespread hype and fear both stem from a fundamental misunderstanding of this principle. They arise from treating the LLM as the entire car, rather than as a critical component within a complex, integrated system. Consequently, organizations measure success with the wrong metrics, focusing on the isolated performance of the engine on a test bench instead of its impact on the car's overall lap time. Below, I try to deconstruct this polarization problem, revealing its origins in a flawed mental model and arguing for a new framework for evaluating success—one centered on workflow enhancement, not standalone AI performance.

The Hype vs. Reality Chasm: A Market Divided
The data on LLM adoption paints a clear picture of this division. The enthusiasm is undeniable: enterprise experimentation with generative AI is soaring, with McKinsey reporting that adoption in at least one business function nearly doubled in less than a year, from 33% in 2023 to 65% in 2024 [1]. Another survey from mid-2023 found that 58% of companies were already experimenting with the technology, driven by the promise of transformative efficiency and innovation [2]. This is the hype cycle in full swing, fueled by compelling public demonstrations and a palpable fear of being left behind.
Yet when we look beyond pilot programs and proof-of-concept stages, a starkly different reality emerges. The same survey that highlighted 58% experimentation found that only 23% of companies had actually moved their LLM applications into commercial production [1]. This significant gap between trying and deploying hints at a deep-seated challenge. The problem becomes even more acute when viewed through the broader lens of enterprise AI initiatives, where a staggering 95-98% are estimated to fail beyond the pilot phase [3]. These failures are not typically due to a single technical flaw but are attributed to a combination of strategic misalignment, inadequate infrastructure, and, most critically, unrealistic expectations of the AI's autonomy [3].
This chasm between hype and reality breeds polarization. Executives who invest based on the hype become disillusioned when their standalone AI chatbot fails to single-handedly reinvent their customer service department. They join the skeptics. Meanwhile, competitors seeing these failures become overly cautious and miss the opportunity to gain genuine competitive advantage. The cycle perpetuates itself, obscuring the productive middle ground where real value is being created.
In our Formula 1 analogy, this is the equivalent of half the teams trying to bolt the new engine onto last year's car, watching it fail spectacularly on the track, and then declaring the engine technology a complete bust. The other half, seeing the failures, decides to stick with their old, reliable engine, falling further behind with every lap.
The "Magic Box" Fallacy: Misunderstanding the Tool
The root cause of this division is a cognitive shortcut I call the "Magic Box" fallacy—the tendency to view an LLM as a self-contained, autonomous intelligence that can be given a complex objective and be expected to achieve it without support or integration. Both the evangelist and the skeptic are victims of this fallacy, though it manifests differently.
The evangelist sees the magic box and believes it can replace entire workflows. They ask, "Can we use an LLM to write all our marketing copy?" or "Can this AI handle our entire sales qualification process?" This approach inevitably leads to disappointment. The LLM, operating in a vacuum without access to real-time customer data, brand guidelines, or the nuanced context held by a human expert, produces generic, inaccurate, or off-brand results. The project is deemed a failure, and the technology is blamed for not living up to its magical promise.
The skeptic sees the failures produced by this flawed approach and concludes that the box is empty. They correctly identify that the LLM hallucinates facts, lacks true reasoning, and cannot be trusted with mission-critical tasks. Their mistake is assuming that these limitations render the technology useless. They are looking at the engine's flaws—its high fuel consumption or narrow power band—and ignoring its revolutionary potential when integrated into a supportive system.
The correct approach is to discard the magic box analogy entirely and embrace the systems-thinking model of the Formula 1 team.
The LLM is the engine. It is brilliant at generating raw power (language, code, ideas) but requires other specialized systems to function effectively:
- The Chassis (Traditional Code & Logic): This is the deterministic software that provides structure. It calls the LLM when its specific capabilities are needed, validates its outputs, and handles tasks that require absolute precision and logic.
- The Driver (Human Expert): This is the human-in-the-loop who provides strategic direction, context, and final judgment. They craft the prompts, review the outputs, and make the critical decisions the AI is not equipped to handle.
- The Pit Crew (Data & Tools): This is the ecosystem of curated data, databases, and external APIs that the LLM can access. Grounding the LLM in high-quality, real-time information is the single most important factor in improving its reliability and relevance.
When an LLM project fails, it is almost never the fault of the engine alone. It is a failure of the system—a failure to build the right chassis, train the driver, or provide the pit crew with the right tools.
Redefining the Finish Line: From AI Performance to Workflow Enhancement
This brings us to the final piece of the polarization puzzle: metrics. Because we have been treating LLMs as magic boxes, we have been measuring their success with the wrong yardstick. We ask questions like, "How often is the AI's answer 100% correct?" or "Can the AI complete this task without human intervention?" These metrics are destined for failure because they measure the tool in isolation and against a standard of perfect, autonomous performance it was never designed to meet.
We must redefine the finish line. The goal is not to build a perfect, all-knowing AI. The goal is to build a faster, more efficient, and more effective organization, teams, and execute tasks. Therefore, our metrics must shift from evaluating the AI's standalone performance to measuring the enhancement of the human-led workflow.
Consider these alternative, system-oriented metrics:
- Instead of: AI Answer Accuracy → Measure: Workflow Error Rate Reduction. Did integrating the LLM to produce first drafts for human review reduce the number of final errors in our financial reports?
- Instead of: Level of Automation → Measure: Time to Completion. By how much did our sales team reduce the time spent on lead qualification now that an LLM assists with initial research and summarization?
- Instead of: Standalone AI Capability → Measure: Expert Time Reallocation. Are our senior engineers spending more time on innovation and complex problem-solving now that an LLM helps them generate boilerplate code and documentation?
In our racing analogy, this is the difference between judging an engine by its raw horsepower on a dynamometer versus its contribution to the car's lap time. An engine with slightly less peak horsepower but better fuel efficiency and a wider torque curve might lead to a faster overall race time by enabling a better pit strategy and improving acceleration out of corners. Success is not defined by one component's peak performance but by the enhanced performance of the entire system.
By moving past the polarized debate and adopting a systems-based approach, business leaders can begin to ask the right questions. The conversation shifts from "Is this technology good or bad?" to "How can we build an effective system around this powerful new component to achieve a specific business outcome?" This is the mindset that separates the teams stuck in the pits from those who will ultimately stand on the podium.
Understanding LLM Capabilities and Inherent Limitations
Having established that a Large Language Model is best understood as a powerful engine within a larger system, we must now look under the hood. For any race strategist or team principal, a deep, unsentimental understanding of their engine's performance characteristics is non-negotiable. They must know its precise power curve, fuel efficiency under different loads, operational tolerances, and—most importantly—its breaking points. Attempting to build a winning strategy without this knowledge is not just optimistic; it is negligent.
Similarly, to effectively integrate an LLM into our business workflows, we must move beyond a surface-level appreciation of its power and develop a nuanced understanding of what it does brilliantly, where it struggles, and why these limitations are inherent to its design. This section provides that essential technical briefing for the non-technical leader. We will dissect the core capabilities of LLMs—their almost supernatural proficiency in pattern recognition and language synthesis—while also clearly defining their inherent weaknesses in areas like complex reasoning and contextual judgment.
By appreciating both sides of this coin, we can begin to design intelligent systems that leverage the engine's strengths for maximum acceleration while building in the necessary guardrails and support systems to prevent it from failing on the track. This is not about diminishing the technology; it is about respecting it enough to use it correctly.
The Power of Probabilistic Pattern Matching
At its core, an LLM is a vast and sophisticated pattern-matching machine. After being trained on a monumental corpus of text and data from the internet, books, and other sources, it does not "understand" language in the human sense. Instead, it develops an incredibly sophisticated statistical model of the relationships between words, phrases, and concepts. When given a prompt, its fundamental task is to predict the most probable sequence of words to come next, based on the patterns it has learned. This is why its capabilities in certain areas feel so remarkable.
LLMs excel at three primary categories of tasks that rely on this probabilistic architecture:
- Language Processing and Synthesis: Because they are masters of linguistic patterns, LLMs are exceptionally skilled at tasks like translation, summarization, rephrasing, and changing the tone of a piece of writing (like the text you are reading right now 😉). They can take a dense technical report and generate a concise executive summary, or convert bullet points from a meeting into a polished, professional email. This is the engine running at peak efficiency, performing the exact task it was built for: manipulating language based on learned patterns.
- Knowledge Retrieval and Synthesis: LLMs can act as powerful knowledge synthesizers. When asked a question, they can draw upon their vast training data to assemble a coherent and comprehensive answer, effectively summarizing information on a given topic. For example, a marketing manager could ask an LLM to generate a report on the key consumer trends in the electric vehicle market, and the model can synthesize a plausible first draft by pulling together countless articles, reports, and discussions it has processed.
- Pattern Recognition and Generation: This extends beyond natural language to other patterned data, such as software code. An LLM can generate boilerplate code, write database queries, or even create formulas for a spreadsheet because these tasks follow predictable structures and syntax. This is the engine's ability to recognize a familiar pattern (e.g., a "for loop" in Python) and complete it accurately.
In our Formula 1 analogy, these capabilities represent the engine's raw horsepower and torque. This is its sweet spot—the RPM range where it delivers explosive power. The technical specifications for a model like GPT-4 confirm its high performance on a wide range of professional and academic benchmarks, from passing the bar exam to complex language understanding tests [4]. However, just as an F1 engine is useless for towing heavy cargo, an LLM's design makes it fundamentally unsuited for tasks that fall outside this pattern-matching paradigm.
The Fragility of Reasoning and the "Hallucination" Problem
The most significant limitation of an LLM is its inability to perform true, multi-step logical reasoning. Because it operates on probability, not logic, it struggles when a task requires a chain of cause-and-effect deductions, mathematical precision, or adherence to a strict set of rules. The model can generate text that looks like a logical argument, but it is merely mimicking the pattern of reasoning it has seen in its training data. It has no internal mechanism to verify if its own conclusions are factually correct or logically sound.
This leads to the widely discussed phenomenon of "hallucinations," where an LLM will state incorrect information with complete confidence. This is not a bug or a sign of deceit; it is a natural byproduct of its design. When the model doesn't have a definitive, high-probability answer in its training data, it "fills in the gaps" by generating the most statistically plausible—but often factually wrong—sequence of words. It is a pattern completer, not a fact checker.
This weakness becomes critically apparent in multi-step business processes. A recent Salesforce study examining the use of LLMs in CRM workflows found that when the models were asked to perform complex, multi-step tasks without human checkpoints, they had a success rate of only 35% [5]. The models would fail by misinterpreting a step, losing context from a previous step, or simply inventing a detail to complete the sequence. This is the equivalent of asking the engine to navigate a series of complex turns on its own; without a driver (human) and a steering system (deterministic code), it will inevitably end up in the wall.
Furthermore, practical constraints like "context windows"—the limited amount of text a model can consider at one time (e.g., around 32,000 tokens for some GPT-4 models, and higher with newer models)—exacerbate this issue [4]. In a long or complex workflow, the model can literally "forget" the instructions or information provided at the beginning, causing the reasoning chain to break down completely.
The Expert's Blind Spot: Why Human Validation is Non-Negotiable
An LLM can access and synthesize a world of information, but it possesses zero real-world experience. It cannot differentiate between high-quality, strategically vital information and plausible-sounding nonsense without proper context and guidance. It can draft a marketing email, but it doesn't understand the subtle competitive pressures or the specific history of your relationship with a key client. It can summarize a legal document, but it has no concept of legal precedent or jurisdictional nuance. This is the expert's blind spot: the critical context, judgment, and wisdom that come only from experience.
For this reason, human validation is not a helpful add-on; it is a mandatory component of any responsible LLM implementation. The LLM should be used to augment the expert, not replace them. It can produce the first 80-90% of a draft, freeing up the human expert to focus their valuable time on the final 10-20%—the part that requires nuance, strategic alignment, and critical thinking.
Think of our race strategist again. The engine's telemetry provides millions of data points per lap—raw information. But this data is meaningless without the strategist's expertise to interpret it. Is a spike in engine temperature a sign of imminent failure, or an expected result of running in another car's slipstream? The data doesn't say; only the expert knows. The LLM provides the raw output; the human expert provides the judgment.
Deconstructing Complexity: The Power of Task Decomposition
So, how do we harness the engine's immense power while respecting its profound limitations? The answer lies in structured task decomposition. Instead of giving an LLM a complex, end-to-end objective, we must break that objective down into a series of smaller, well-defined sub-tasks and assign each one to the appropriate component of our system.
A complex workflow like "Process a new customer complaint" should not be handed to an LLM as a single command. Instead, it should be deconstructed:
- Step 1 (LLM): Ingest the customer's email. Summarize the key issue and classify its sentiment (e.g., angry, frustrated, disappointed).
- Step 2 (Traditional Code): Take the customer's email address and query the CRM database to retrieve their order history and support ticket record.
- Step 3 (Human Expert): Review the LLM's summary alongside the customer's history. Make a strategic judgment about the priority and nature of the response required.
- Step 4 (LLM): Based on the expert's instructions (e.g., "Draft a polite, apologetic response offering a 15% discount"), generate a first draft of the reply email.
- Step 5 (Human Expert): Edit and approve the final email before it is sent.
This approach, often called a "human-in-the-loop" system, plays to everyone's strengths. The LLM handles the repetitive language tasks, the traditional code handles the deterministic data retrieval, and the human provides the critical judgment and oversight. A proof-of-concept for managing complex semiconductor failure analysis workflows demonstrated this principle effectively, using an LLM not as a standalone solver but as a component integrated with planning tools and a structured process to navigate the analysis [6].
By understanding our engine—celebrating its power for pattern matching while respecting its inability to reason or exercise judgment—we can stop trying to make it do the whole lap on its own. We can instead begin the real work of a championship team: designing a complete system where every component, from the engine to the driver, performs its role flawlessly.
The Systems Integration Framework: LLMs as Workflow Components
In the preceding sections, we established a critical foundational concept: a Large Language Model is not a complete solution, but rather a high-performance engine. We explored its remarkable power for language and pattern synthesis, as well as its inherent limitations in reasoning and judgment. This understanding frees us from the polarized debate of hype versus fear and allows us to ask a much more productive question: If the LLM is our engine, how do we build the rest of the championship-winning Formula 1 car around it?
An engine, no matter its horsepower, is useless without a system to translate its power into controlled, reliable, and strategic performance on the track. It requires a chassis, a driver, a race strategy, and a pit crew. In my experience, the most common reason for the high failure rate of AI initiatives is the neglect of these other components. Organizations attempt to bolt the engine directly to the wheels and are then shocked when the result is not a race car but an uncontrollable, unreliable machine.
This section provides the blueprint for that complete system. Below, I outline a five-part Systems Integration Framework that treats the LLM as a core component within a broader, more intelligent workflow. This is not a technical manual for developers but a strategic guide for managers on the essential, non-negotiable elements required to move from a sputtering proof-of-concept to a high-performance, value-generating business asset. Adopting this framework is the difference between merely experimenting with AI and systematically succeeding with it.

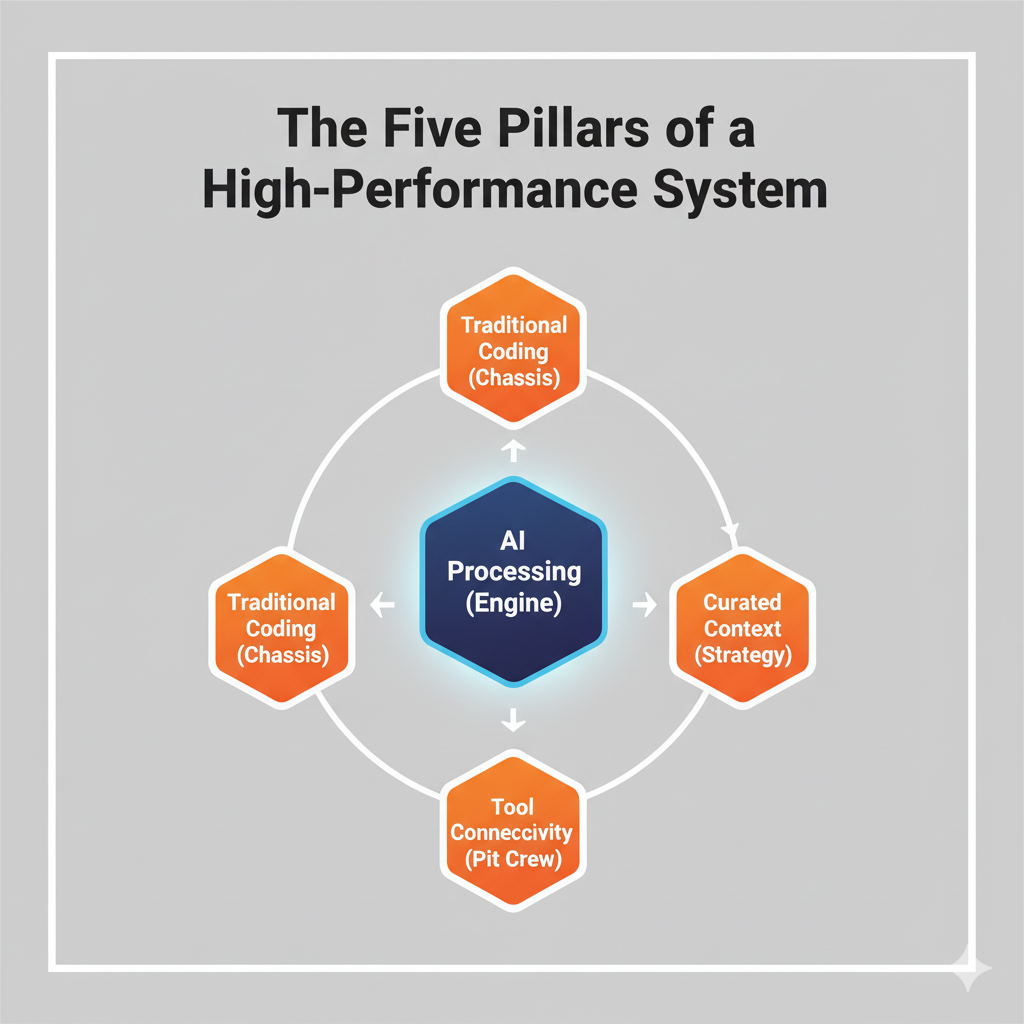
The Five Pillars of a High-Performance LLM System
Just as a Formula 1 car is an integrated marvel of engineering, a successful LLM implementation is a carefully orchestrated system of five distinct but interconnected pillars. Leaving any one of these pillars underdeveloped is like trying to race with only three wheels; the entire system becomes unstable and destined to fail. The most effective implementations I have seen consciously design and manage each of these five components in concert.
- AI Processing (The Engine): This is the LLM itself—the core generative component. As discussed, its role is to handle the probabilistic tasks: drafting text, summarizing information, generating code, brainstorming ideas, and identifying patterns. It is the source of raw power, but its output is inherently a first draft, a suggestion, or a piece of raw material that requires shaping and validation by the rest of the system.
- Traditional Coding (The Chassis and Drivetrain): This represents the deterministic, rule-based software that surrounds the LLM. This is the rigid, predictable architecture of your existing applications and new code written to manage the workflow. Its job is to handle tasks that require 100% accuracy and logic: performing mathematical calculations, retrieving specific data from a database, validating user input, and executing transactions. This code forms the chassis that provides structure and the drivetrain that translates the engine's raw power into controlled motion. It calls the LLM when its creative capabilities are needed and takes over when precision is paramount.
- Expert Oversight (The Driver): This is the non-negotiable human-in-the-loop. The expert is the skilled professional who provides strategic direction, nuanced judgment, and final sign-off. They are not just a passive reviewer at the end of the process; they are the driver, actively steering the system, interpreting the data, and making critical decisions at key moments. Their domain knowledge is the one thing the LLM cannot replicate, and their oversight is what transforms a probabilistic output into a trusted business asset.
Curated Context (The Race Strategy and Telemetry): An LLM operating without specific, high-quality context is like a driver with no race plan and a blacked-out dashboard. This pillar encompasses the disciplined practice of providing the LLM with the precise information it needs to perform a task effectively. This includes meticulously crafted prompts (prompt engineering), grounding the model with relevant documents and data (Retrieval-Augmented Generation, or RAG), and providing clear examples of the desired output. This is the race strategy, the track notes, and the real-time telemetry data that guide every decision.
- Tool Connectivity (The Pit Crew): A race car is not a closed system; it relies on a pit crew for fuel, tires, and repairs. Similarly, an LLM system must be connected to the outside world. This pillar represents the APIs (Application Programming Interfaces) and data connectors that allow the LLM workflow to access real-time information from external systems (like a CRM, ERP, or inventory database) and to take action in those systems (like creating a support ticket or updating a customer record). This connectivity is what makes the system dynamic and impactful.
Organizations that achieve significant returns on their AI investments do so by orchestrating these five pillars. A case study of bespoke LLM agents developed by Cognizant highlights that combining these components is key to driving ROI across business workflows [6]. Similarly, another analysis of enterprise integration practices found that cohesive systems can deliver an average operational cost reduction of 47% and achieve user adoption rates as high as 94% by ensuring the technology is reliable, useful, and embedded within familiar processes [7].
The Driver at the Wheel: Strategic Human-in-the-Loop Checkpoints
The concept of "human-in-the-loop" is often misunderstood as simply having a person check the AI's work at the very end. This is a dangerously simplistic view. A truly effective system integrates expert oversight at strategic checkpoints throughout the workflow, not just at the finish line. This approach dramatically improves quality and reliability, with some analyses showing that well-placed human checkpoints can reduce critical errors by up to 60% [6].
Let's revisit the customer complaint workflow from the previous section to see this in practice. A poor implementation might have the LLM read the complaint, look up the customer, and draft and send a reply, all in one automated step. This is a recipe for disaster. A robust, five-pillar system would look very different:
- Checkpoint 1 (Strategy): The workflow begins. The LLM (Engine) summarizes the incoming email. The Traditional Code (Chassis) retrieves the customer's full order history from the database. Both pieces of information are presented to a human customer service agent (Driver). The agent makes a critical judgment: Is this a high-value, at-risk customer? Is the issue a simple one or does it require escalation? This initial human decision sets the strategy for the entire interaction.
- Checkpoint 2 (Validation): Based on the agent's instruction (e.g., "Offer a full refund and a 20% discount on their next order"), the LLM (Engine) drafts a response. The draft is not sent automatically. It is presented back to the agent. The agent reviews it for tone, accuracy, and brand voice. They might make a small edit to add a personal touch based on their prior knowledge of the customer. This is the validation checkpoint.
- Checkpoint 3 (Execution): Once the agent approves the email, they click "Send." This triggers the Traditional Code (Chassis) and Tool Connectivity (Pit Crew) to execute the actions: the email is sent, the refund is processed in the payment system via an API call, and a note is logged in the CRM. The human provides the final authorization for action.
In this model, the human expert is not a bottleneck; they are a force multiplier. They are performing only the tasks that require their unique judgment and expertise, while the AI and traditional code handle the repetitive, time-consuming work. This elevates the role of the employee from a process-follower to a strategic decision-maker, which is the ultimate goal of workflow enhancement.
The Unseen Architecture: Context Curation and Prompt Engineering
Perhaps the most underestimated pillar is that of curated context. There is a prevailing myth that interacting with an LLM is as simple as casual conversation. In a consumer setting, this is often true. In a business setting, where accuracy, consistency, and reliability are paramount, this assumption is a primary cause of failure. Context curation and prompt engineering require as much strategic planning and rigor as traditional software architecture.
When a software architect designs a system, they create blueprints for how data will be structured, stored, and accessed to ensure the application behaves predictably. A "context architect" does the same for the LLM. They design the flow of information to and from the model to constrain its probabilistic nature and guide it toward the desired, high-quality output. This involves several key activities:
- Prompt Engineering: This is the craft of designing detailed, structured instructions for the LLM. A good prompt is not a simple question; it is a comprehensive brief that includes the user's request, the desired format and tone of the output, constraints (e.g., "Do not mention competitors"), and examples of what a good answer looks like.
- Context Grounding: This involves providing the LLM with a curated set of relevant, factual documents to use as its source of truth for a given task. For an HR chatbot answering employee questions, this would mean feeding it the official employee handbook and benefits documentation, rather than letting it rely on its general training data. This dramatically reduces hallucinations and ensures answers are aligned with company policy.
- Workflow Integration: This is the design of the handoffs between the LLM, the human expert, and the traditional code. The architect must decide what information is passed at each step to preserve context and ensure the next component in the chain has what it needs to function correctly.
Failing to invest in this discipline is like giving your Formula 1 driver a blank map and wishing them luck. The performance will be erratic and unpredictable. By treating context as a formal architectural layer, organizations can build systems that are not only powerful but also reliable, consistent, and safe. This systematic approach is what unlocks the 2-4x efficiency gains reported in successful cross-departmental use cases, from customer service to data analytics [7].
In conclusion, the path to LLM success does not run through a single piece of technology. It is paved by a holistic, systems-based approach. By deliberately designing and integrating all five pillars—AI Processing, Traditional Coding, Expert Oversight, Curated Context, and Tool Connectivity—leaders can build a complete, high-performance machine. This is how we move beyond the hype and fear, and begin the real work of building organizations that are faster, smarter, and more effective.
Implementation Architecture: Building Effective LLM-Integrated Workflows
Having established the five-pillar Systems Integration Framework in the previous section, we now move from the strategic blueprint to the engineering bay. We have identified our core components: the LLM as the Engine, traditional code as the Chassis, the human expert as the Driver, curated context as the Race Strategy, and tool connectivity as the Pit Crew. The critical question that follows is: How do we assemble these parts into a cohesive, high-performance machine?
A collection of world-class components is not a race car; it is a pile of expensive parts until a deliberate, intelligent architecture connects them into a functional whole. This is where many promising LLM initiatives falter. The focus remains so heavily on the power of the engine that the design of the transmission, the integrity of the wiring harness, and the reliability of the braking system are treated as afterthoughts. In my experience, a successful implementation is defined not by the peak power of its LLM, but by the robustness and elegance of its underlying architecture.
This architecture is what transforms the probabilistic, creative nature of the LLM into a reliable, auditable, and scalable business process. This section provides the architectural principles for building these integrated workflows. We will explore the non-negotiable practices of task decomposition, the power of connecting our system to live data and tools, and the essential quality control mechanisms required to maintain performance over time. This is the engineering discipline that turns a promising prototype into a championship-winning asset that consistently delivers value, lap after lap.

The Assembly Line: Decomposing Workflows for Reliability
The first principle of sound LLM architecture is the disciplined decomposition of complex tasks. As we discussed, giving an LLM a vague, multi-step objective is like telling an engine to win the race by itself. The architectural solution is to design a workflow that functions like a modern assembly line, where a complex product is built through a series of discrete, specialized stations. Each station has a clear input, a specific task to perform, and a well-defined output that it hands off to the next station. In our system, these stations can be an LLM, a piece of traditional code, or a human expert.
The "chassis" of our system—the traditional, deterministic code—acts as the assembly line's conveyor belt and master controller. It orchestrates the entire process, ensuring that each step is executed in the correct sequence and that information is passed cleanly between stations. This approach provides two crucial benefits: reliability and auditability.
Consider our recurring example of processing a customer complaint. A robust architectural flow would look like this:
- Station 1 (Code - Ingestion): An incoming email arrives. The code module receives it, assigns it a unique tracking ID, and saves the raw email and its metadata into a database. This act of creating a persistent record is the foundational step; without it, the process is untraceable.
- Handoff A: The code module packages the email text and the tracking ID into a structured request for the LLM.
- Station 2 (LLM - Analysis): The LLM receives the request. Its sole, clearly defined task is to read the text and output a structured JSON object containing a one-sentence summary, a sentiment analysis (e.g., "angry," "disappointed"), and a categorization of the issue (e.g., "shipping delay," "product defect").
- Handoff B: The LLM returns the JSON object. The code module immediately validates it. Does it have the required fields? Is the sentiment one of the approved values? If the validation fails, the process can be flagged for manual review. If it succeeds, the structured data is saved to the database, linked to the original tracking ID.
- Station 3 (Human - Judgment): The user interface now displays the original email, the LLM's summary, and the customer's history (retrieved by code from the CRM) to the human expert. The expert's station is designed for one purpose: to make a strategic decision.
This modular, step-by-step process, with clear handoffs managed by deterministic code, transforms an unpredictable interaction into a reliable workflow. Every step is logged, every output is validated, and the state of the process is always maintained in a database. This is how you build a system that is resilient to the inherent variability of an LLM.
The Pit Crew Connection: Integrating Data and External Tools
An LLM's base knowledge is a snapshot of the past, derived from its training data. For it to be truly effective in a business context, it must be connected to the dynamic, real-time world of your operations. This is the role of our "Pit Crew"—the database integrations and external tool connections (APIs) that provide the system with live data and the ability to take action. This connectivity multiplies the LLM's effectiveness exponentially.
Database integration is the most fundamental connection. An LLM can be architected to act as a brilliant "universal translator" for your company's data. Through a technique known as Natural Language-to-SQL, a manager can ask a question in plain English, such as, "Compare our sales figures for Product Z in the New York and Boston regions for the last quarter." The LLM's role is not to know the answer, but to translate that English question into a perfectly formed SQL query. The traditional code layer then executes this query against your sales database, retrieves the actual data, and can even pass it back to the LLM to be presented in a summarized, easy-to-read format.
This democratizes data access, turning every manager into their own data analyst without them ever having to write a line of code.
Beyond retrieving data, a robust architecture allows the LLM system to act. This is achieved through APIs, which are secure gateways that allow different software systems to communicate and perform actions. By giving our workflow access to these tools, we empower it to complete tasks, not just analyze them. For example, after the human expert approves the customer complaint response, the system can use an API to:
- Log the interaction in your Salesforce CRM.
- Create a refund transaction in your Stripe payment system.
- Generate a shipping label for a replacement product in your ShipStation software.
Building this connective tissue is a specialized engineering task, but its payoff is immense. A case study on enterprise LLM integration found that using well-designed middleware frameworks to manage these connections can reduce integration time by up to 65%. Furthermore, by optimizing how and when the LLM is called, these integrated systems can reduce operational token usage costs by an average of 47% [7]. This is a clear demonstration that investing in the architecture around the LLM provides a direct and measurable return.
The Quality Control Bay: Versioning and Validation for Continuous Improvement
In Formula 1, a car's design is never finished. After every race, it is brought back to the factory, where every component is inspected and performance data is analyzed to find opportunities for improvement. A professional LLM implementation requires the same commitment to continuous quality control and iterative improvement. Because LLMs are non-deterministic (the same input can produce slightly different outputs), traditional software testing methods are insufficient. We must build a new kind of quality control bay.
This starts with treating our prompts like code. A prompt is not a casual question; it is a carefully engineered instruction set that dictates the LLM's behavior. As such, prompts must be placed under version control. This means every change to a prompt is tracked, documented, and tested. If a new version of a prompt causes a decrease in output quality, the team can immediately roll back to the previous, stable version. This discipline transforms prompt engineering from an art into a managed engineering process.
Next, we must implement a layer of automated output validation. This is a set of deterministic checks, written in traditional code, that acts as an automated inspector for every LLM response before it is used. This validation layer can perform critical checks, such as:
- Structural Validation: Does the output conform to the required format (e.g., is it valid JSON)?
- Content Validation: Does the response contain any sensitive information (like personally identifiable information) that should be redacted?
- Safety Validation: Does the text meet brand safety and compliance standards, checking for toxicity or inappropriate language?
- Constraint Validation: Does the output adhere to the constraints given in the prompt (e.g., is the summary under the 50-word limit)?
Finally, this architecture must create a tight feedback loop. When a human expert in the workflow corrects or edits an LLM's output, that is not a failure—it is valuable data. A well-architected system logs these corrections, creating a rich dataset that shows exactly where the prompts or the model are falling short. This data is the fuel for iterative improvement, allowing the engineering team to refine prompts, fine-tune models, and systematically increase the quality and reliability of the system over time.
In conclusion, the architecture of an LLM-integrated workflow is what instills the discipline, reliability, and maintainability necessary for enterprise success. By decomposing complex tasks, deeply integrating with data and tools, and building robust mechanisms for versioning and validation, we construct a system that is far greater than the sum of its parts. This is how we move beyond simply having a powerful engine and begin to field a complete, championship-caliber machine capable of consistently outperforming the competition.
User Competency: The Critical Success Factor
Throughout this white paper, I have followed the analogy of building a Formula 1 race car. We have engineered a revolutionary engine (the LLM), designed a robust chassis and drivetrain (the traditional code), and blueprinted a sophisticated architecture to connect every component into a cohesive whole. We have, in essence, assembled a machine with championship potential. But a Formula 1 car sitting in the garage, no matter how technologically advanced, is merely a monument to potential. To win the race—to generate real, measurable value—it needs a driver. And the skill of that driver is the final, and arguably most critical, determinant of its success on the track.
In our integrated system, the user is the driver. This is not a trivial role. The widespread adoption of consumer-facing chatbots has created a dangerous misconception in the enterprise: that interacting with generative AI is an inherently intuitive, plug-and-play activity requiring no special skill. This is a deeply flawed assumption that lies at the heart of many failed implementations. From my perspective, the value an organization derives from its LLM investment is directly and powerfully correlated with the sophistication of its users.
This section will argue that user competency is not a "soft skill" or a secondary concern, but a core strategic capability that must be systematically developed. We will explore the essential skills that separate a novice user from an expert operator and make the case that investing in training your people is as crucial as investing in the technology itself. After all, the most advanced car in the hands of an amateur will be easily outpaced by a lesser machine piloted by a world-class driver.
Beyond the "Go Button": The Myth of Plug-and-Play Usability
The allure of the simple chat interface is deceptive. It suggests that obtaining valuable output from an LLM is as easy as asking a question. While this is true for casual queries, it breaks down completely when applied to complex, high-stakes business workflows. Expecting an untrained employee to generate reliable, strategically aligned output from an enterprise LLM is like giving a newly licensed driver the keys to a Formula 1 car and expecting them to set a qualifying lap record. They may be able to start the engine and even navigate the track slowly, but they lack the nuanced skills to push the machine to its limits. More likely, they will spin out at the first corner.
An expert user, our trained driver, understands that the LLM is not a simple question-and-answer machine but a powerful co-pilot that must be skillfully guided. Their expertise manifests in three core competencies that must be cultivated:
- Prompt Engineering: This is the ability to craft clear, precise, and context-rich instructions. A novice asks, "Write a marketing email." An expert asks, "Acting as a senior marketing manager for a B2B SaaS company, write a 150-word email to a cold lead in the manufacturing sector. The goal is to secure a 15-minute discovery call. Use a professional but approachable tone, highlight our key value proposition of reducing operational downtime by up to 20%, and end with a clear call-to-action that links to a Calendly scheduling page." The difference in the quality of the output is not marginal; it is profound.
Context Management: An LLM's performance is critically dependent on the information it is given. An expert user knows how to provide the right "telemetry" to the model. This involves grounding the LLM with specific documents (like a project brief or a customer's support history), providing examples of high-quality outputs, and understanding how to structure a conversation to maintain context over multiple turns. They are, in effect, the race strategist, feeding the driver the critical information needed to navigate the next turn.
Result Interpretation and Refinement: Perhaps the most important skill is the ability to critically evaluate the LLM's output. An expert treats every response not as a final answer, but as a high-quality first draft from a brilliant but inexperienced assistant. They instinctively check for factual accuracy, assess for strategic nuance, and refine the output to align with their own deep domain knowledge. The novice accepts the output at face value; the expert collaborates with it.
Failing to recognize the need for these skills is a primary cause of disillusionment. When outputs are generic, inaccurate, or unhelpful, the blame is often placed on the technology. In reality, the failure is often one of usability—a mismatch between the power of the tool and the skill of the operator.

Training the Driver: From Casual User to Expert Operator
If user skill is a direct driver of ROI, then it follows that organizations must treat user training as a formal, strategic investment, not an optional add-on. The data on this is unequivocal: structured user training directly translates to better AI performance. A recent technical study focusing on enterprise LLM training pipelines revealed that formal training can reduce model hallucinations by 30% and improve task completion accuracy by 25% [8]. These are not soft metrics; they are hard, measurable improvements in the reliability and effectiveness of the entire system.
The same study detailed the development of a training pipeline for employees using an LLM for specific, function-related tasks within an HR scenario. The results were remarkable: with targeted training, users were able to elicit performance from the LLM that surpassed the baseline capabilities of even the most powerful general models, like GPT-4, on those specific domain tasks [8]. This provides powerful evidence for a critical conclusion: a well-trained user can elevate the performance of your existing technology beyond its out-of-the-box capabilities.
Therefore, leadership must reframe training not as a cost center, but as an investment that unlocks the latent value in your technology stack. A comprehensive capability development program should include:
- Foundational Concepts: Teaching users the "why" behind the technology—its strengths, its inherent limitations (like the tendency to hallucinate), and the systems-based approach the organization is taking.
- Practical Skills Workshops: Hands-on training in prompt engineering, context management, and critical output evaluation, tailored to specific job roles and common use cases.
- Best Practice Libraries: Creating and maintaining an internal repository of exemplary prompts, successful workflow patterns, and lessons learned that can be shared across teams.
- Continuous Learning Loops: Establishing channels for users to provide feedback on what works and what doesn't, allowing for the continuous refinement of both the training programs and the underlying LLM architecture.
Investing in the car without investing in the driver is a strategy for mediocrity. The true competitive advantage will go to the organizations that build a culture of expert operators who can extract maximum performance from their tools.
The Art of the Ask: What to Ask and How to Use the Answer
Ultimately, user competency boils down to a two-part skill that should be the mantra of every training program: knowing what to ask, and knowing how to effectively utilize the response.
Knowing what to ask is about strategic task selection. A skilled user understands the principle of task decomposition. They do not give the LLM a broad, ambiguous goal like, "Develop a new marketing strategy." They recognize that this task is composed of sub-tasks, some of which are perfect for an LLM and some of which require human expertise. They will instead ask the LLM to perform a series of discrete tasks: "Analyze these three competitor websites and summarize their primary marketing messages," followed by, "Based on this analysis, brainstorm five potential slogans for our new product," and then, "Draft a project plan for a campaign launch based on this template." They use the LLM for ideation, summarization, and drafting, reserving the core strategic decision-making for themselves.
Knowing how to use the answer is about active collaboration. The output of the LLM is an input into a broader human-led workflow. A marketing manager who uses an LLM to draft a social media post does not simply copy and paste the result. They use it as a starting point, refining the language to match the brand's voice, verifying that any product claims are accurate, and adding a timely, relevant hashtag based on their own industry knowledge. They are the final checkpoint, the expert who integrates the AI's contribution into a polished, reliable final product.
In conclusion, as we assemble our high-performance LLM systems, we cannot afford to overlook the person in the driver's seat. The technology itself provides the potential for speed, but it is the competency of the user that delivers the performance. By moving beyond the myth of plug-and-play usability and investing seriously in developing skilled operators, we complete our system. A systems-thinking approach is not just about integrating technology; it is about creating a seamless, powerful partnership between human and machine. The ultimate competitive advantage will not be found in the LLM you procure, but in the capabilities you build within your people.
Practical Implementation Guidelines and Best Practices
We have now reached the final and most crucial stage of our journey. Over the preceding sections, we have meticulously designed our high-performance system, moving from a conceptual blueprint to a fully realized machine. We deconstructed the LLM to understand it as a powerful but specialized engine. We architected a robust chassis of traditional code and integrated the essential pit crew of data and tools. Most importantly, we placed a skilled and well-trained driver—the competent user—in the cockpit. Our Formula 1 car is now assembled, polished, and sitting on the starting grid. All the theory, strategy, and engineering now face their ultimate test: the race itself.
This is the point where strategy meets execution, and where many well-intentioned AI initiatives either achieve victory or spin out on the first lap. A brilliant car and a talented driver are not enough to guarantee a championship; they require an equally brilliant race-day operations plan. This section provides that plan. It is the team's operational playbook, outlining the practical, on-the-ground disciplines required to move from a promising system to a consistent, value-generating winner.
From my experience, organizations that succeed are not those with the most powerful technology, but those with the most disciplined methodology. We will now detail the three core practices of that methodology: starting with a well-chosen first race, defining the true measure of a fast lap, and institutionalizing the post-race debrief for continuous improvement.
Choosing Your First Race: The Power of Bounded Use Cases
A new Formula 1 team, no matter how ambitious or well-funded, would never choose the treacherous, narrow streets of the Monaco Grand Prix for its debut race. To do so would be to invite catastrophic failure. Instead, they begin with controlled shakedown tests, private practice sessions, and perhaps a race on a simpler, more forgiving circuit. The goal is not to win the championship on day one, but to test the car, validate the systems, build team coordination, and secure a small, crucial victory to build momentum. The same principle applies with absolute force to LLM implementation.
The single greatest tactical error I see organizations make is attempting to "boil the ocean." Driven by the transformative hype, they target vast, complex, and ill-defined goals like "automating the entire customer service function" or "reinventing our sales process." This is the Monaco strategy, and it is almost always doomed. A successful implementation begins by selecting a clearly defined, tightly bounded, and strategically valuable first use case. The objective is to get on the board with a quick, tangible win.
A strong initial use case has three defining characteristics:
- High Impact, Low Complexity: It addresses a genuine and recognized business pain point but does not require the LLM to perform complex, multi-step reasoning. The ideal target is a task that is repetitive, time-consuming, and language-centric. For example, instead of the broad goal of automating sales, a perfect bounded use case would be: "Summarize recorded sales call transcripts into a standardized format for entry into the CRM." This saves account executives significant time, improves data quality, and leverages the LLM's core strength in summarization without asking it to make complex strategic decisions.
- Human-in-the-Loop by Design: The best starting points are workflows that already have an expert at their center. This allows the LLM to be introduced as an assistant or a co-pilot, rather than a replacement, making adoption smoother and safer. The goal is augmentation, not automation. For instance, rather than having an LLM handle legal contract review, a better first step is to have it identify specific clauses in a contract for a human lawyer to review, dramatically speeding up their process.
- Measurable and Contained: The workflow should have clear inputs and outputs that allow for straightforward measurement of impact. It should also be relatively self-contained, minimizing complex dependencies on other departments or systems in the initial phase. This de-risks the project and makes it easier to prove value.
By starting with a series of smaller, well-chosen races, an organization achieves several critical objectives. It minimizes the risk of a high-profile failure that could poison internal sentiment towards AI. It allows the team to learn and refine its five-pillar system in a lower-stakes environment. And most importantly, it delivers tangible value quickly, building the credibility and organizational momentum needed to tackle more complex challenges down the road.
Redefining the Lap Time: Measuring Workflow Enhancement, Not Engine RPM
As we established in the first section of this paper, a common cause of failure is measuring success with the wrong yardstick. An engineering team that judges its engine solely by its peak horsepower on a test bench might miss the fact that its poor fuel efficiency makes it uncompetitive over a full race distance. The metric that matters is not the performance of a single component in isolation, but the performance of the entire system towards its objective: the lap time.
In business, the lap time is the efficiency and effectiveness of our workflows. Therefore, our measurement framework must shift its focus from narrow AI accuracy metrics to a holistic evaluation of workflow improvement. While it is tempting to ask, "How often was the LLM's answer 100% correct?", this is the wrong question. A more valuable question is, "By how much did our team's final, human-approved output improve in speed and quality?"
To create a meaningful ROI framework, I advise leaders to build a balanced scorecard that combines quantitative and qualitative measures. This approach provides a complete picture of the system's impact and has been shown to yield measurable returns within three to six months when implemented systematically [9].
Quantitative Metrics (The Lap Time and Telemetry):
- Time Savings: The most direct measure of efficiency. What was the average time to complete the target workflow before and after the LLM integration? (e.g., time to resolve a support ticket, time to draft a project proposal).
- Throughput Increase: How many more units of work can be completed in the same period? (e.g., number of marketing campaigns launched per quarter, number of leads qualified per week).
- Error Rate Reduction: In the final, delivered product, has the introduction of the LLM assistant led to a decrease in human errors? This measures the system's impact on quality.
Qualitative Metrics (The Driver's Feedback and Team Morale):
- User Adoption and Satisfaction: Are employees actually using the tool? Do they trust it? Simple surveys, adoption rate tracking, and direct feedback sessions are crucial for measuring whether the system is genuinely helpful or just another piece of mandated technology.
- Expert Time Reallocation: This is a powerful strategic metric. Are your most valuable experts spending less time on mundane, repetitive tasks and more time on high-value work like strategy, innovation, and complex problem-solving? This shift represents one of the highest forms of ROI.
By adopting this balanced scorecard, the conversation shifts from a technical debate about AI accuracy to a business discussion about performance. It aligns the technology initiative directly with the strategic goals of the organization and provides the clear, compelling evidence needed to justify further investment.
The Post-Race Debrief: Building Iterative Feedback Loops
For a professional racing team, the work is not over when the car crosses the finish line. In many ways, the most important work is just beginning. In the post-race debrief, engineers, strategists, and the driver gather to meticulously analyze every piece of telemetry data, every decision made, and every component's performance. This relentless process of analysis and feedback is what drives the continuous improvement that separates champions from the rest of the field. An LLM implementation must be managed with the same discipline.
Deploying an LLM-integrated workflow is not a one-time event; it is the beginning of a continuous cycle of refinement. The system is a living entity that must be monitored, tuned, and improved. Building robust, iterative feedback loops is the mechanism that drives this evolution.
An effective feedback loop consists of three key activities:
- Systematic Performance Monitoring: This involves actively tracking the quantitative and qualitative metrics defined in your scorecard. Dashboards should be created to visualize performance against the pre-implementation baseline, making it easy to spot trends, identify successes, and flag potential issues.
- Rigorous Error Analysis: When a user has to significantly correct an LLM's output, it should be treated not as a failure, but as valuable telemetry data. The system architecture should make it easy to log these corrections. A dedicated team should regularly analyze these instances to diagnose the root cause. Was the prompt unclear? Was the grounding context insufficient? Is this a fundamental limitation of the current model? This analysis provides a precise roadmap for improvement.
- Structured Refinement Cycles: Based on the data from monitoring and error analysis, the team must engage in a regular, scheduled cycle of refinement. This is not an ad-hoc process. It is a disciplined cadence (e.g., a bi-weekly sprint) dedicated to taking concrete actions like re-engineering prompts, updating the curated context documents, or even adjusting the workflow logic in the traditional code layer. This ensures the system doesn't stagnate but continuously adapts and improves based on real-world performance.
This commitment to a continuous feedback loop transforms the organization into a learning system. Every interaction with the technology becomes an opportunity to make it smarter, more reliable, and more valuable. It is this relentless, iterative process that ensures the initial investment in AI pays dividends long into the future, keeping you ahead of the competition.
In conclusion, the path from a promising technology to a tangible business advantage is paved with operational discipline. By starting with bounded, high-impact use cases, measuring the true impact on workflow performance, and committing to a relentless cycle of feedback and refinement, leaders can navigate the complexities of LLM implementation successfully. This is the race strategy that wins championships—not through a single silver bullet, but through a sustained commitment to excellence in execution.
Strategic Recommendations and Future-Proofing Your LLM Investment
We have now completed our final lap of the circuit. Throughout this journey, we have moved from the polarized discourse of the grandstands to the focused reality of the engineering bay and the pit wall. We began by reframing the Large Language Model not as a magic box, but as a powerful engine—a component with incredible potential and distinct limitations. We then meticulously designed the rest of the car: a robust chassis of traditional code, a skilled driver in the form of a competent user, a brilliant race strategy of curated context, and a high-performance pit crew of connected tools. Finally, we outlined the race-day disciplines needed to execute flawlessly, from choosing the right first race to establishing a culture of post-race analysis.
Our car is built, our driver is trained, and our strategy is set. The final task for any team principal is to look beyond the next race and consider the entire championship season—and the seasons that will follow. The world of generative AI is not a static environment; the rules, the technology, and the competition are evolving at an unprecedented pace. From my perspective, the long-term winners in this new era will not be the organizations that simply acquire the most powerful engine of the moment. Victory will belong to those who build the most sophisticated, adaptable, and intelligent racing organization.
This concluding section provides the strategic framework for doing just that, ensuring your significant investment in AI today yields a durable competitive advantage for years to come.
The Shift from Technology Acquisition to Capability Cultivation
The first and most critical strategic shift leaders must make is to move from a mindset of technology acquisition to one of capability cultivation. In the current market, the temptation is to focus the entire AI strategy on a single question: "Which LLM platform should we buy?" This is the equivalent of believing the entire outcome of a Formula 1 season rests on which engine supplier you choose. While an important decision, it is a dangerously incomplete strategy. The underlying LLM technology is rapidly becoming commoditized. The performance gap between major models is narrowing, and new, powerful open-source alternatives are emerging constantly. A strategy based solely on having the "best" model is a strategy for temporary, fleeting advantage at best.
The durable, defensible advantage lies not in the engine you procure, but in the organizational capabilities you build around it. Sustainable success requires an unwavering organizational commitment to mastering the five pillars of our Systems Integration Framework, transforming them from project components into core business competencies:
- AI Evaluation Competency: Instead of just buying a platform, build the internal skill to continuously evaluate, benchmark, and select the right AI models for specific tasks. This means your organization can flexibly adopt a powerful new model for creative text generation while using a smaller, faster, and cheaper model for internal summarization tasks.
- Integration Architecture Competency: Cultivate a world-class engineering culture focused on building the modular, deterministic "chassis" we described. This is the expertise to create robust workflows, manage data flow, and ensure the reliability and auditability of your AI-integrated systems.
- Human Judgment as a System: Foster a culture that explicitly values and integrates expert oversight. This means designing processes and user interfaces that empower your people to be effective "drivers," making it easy for them to provide the critical context and validation that the AI lacks.
- Context Design as a Discipline: Elevate prompt engineering and context management from a casual activity to a formal discipline. This involves training "context architects" who, like software architects, design the flow of information to and from the LLM to ensure consistent, high-quality, and on-brand outputs.
Committing to this path means recognizing that you are not simply installing new software. You are fundamentally upgrading your organization's operational DNA. It is a commitment to systems thinking and continuous learning that pays dividends long after the initial hype of a new model has faded.
Architecting for the Future: Why Integration is the Only Defense Against Obsolescence
The generative AI market is projected to grow at a compound annual growth rate of nearly 80% through 2030 [2]. This explosive growth guarantees one thing: constant, disruptive change. The state-of-the-art model today will be an industry baseline in eighteen months and potentially obsolete in three years. Any organization that builds its entire AI strategy by deeply embedding a single, monolithic LLM into its core processes is building on technological quicksand. When that specific model or platform becomes outdated, they face the monumental task of ripping out and rebuilding their entire system.
Future LLM evolution will unequivocally favor organizations with robust, modular integration architectures over those seeking standalone solutions. The systems-based approach we have detailed is, by its very nature, a future-proofing strategy. By designing a system where the LLM is a distinct component—the engine—plugged into a larger chassis, you create strategic agility. This modular architecture allows you to "swap the engine" without rebuilding the entire car.
Imagine a scenario two years from now where a new LLM emerges that is ten times cheaper and twice as fast for a specific task your business relies on. For the organization with a standalone, deeply embedded solution, migrating is a massive, cost-prohibitive project. For the organization with a modular architecture, the process is comparatively simple. Because the workflow logic, the user interface, the database connections, and the human checkpoints are all part of the independent chassis, the migration becomes a focused engineering task of updating the API calls to the new model. You can adopt the best-in-class technology of the future with minimal disruption to the business.
This is why the future belongs to the integrators. As the pace of AI adoption continues to accelerate, with nearly two-thirds of organizations already using it in some capacity [1], simply having the technology ceases to be a differentiator. The competitive edge will be defined by the speed and efficiency with which an organization can absorb the next wave of innovation. A flexible, integrated architecture is the essential foundation for that adaptive capability.
A New Investment Thesis: Prioritizing People and Process over Platforms
To execute this strategy, leaders must adopt a new investment thesis for AI. The traditional IT procurement model, which heavily weights the upfront capital expenditure on the software platform, is ill-suited for the generative AI era. A forward-thinking investment plan must be rebalanced to reflect the reality that the platform is only one piece of a much larger value equation.
I propose a rebalanced investment portfolio for any serious LLM initiative, with the focus shifting from the technology itself to the human and process capabilities that unlock its value:
- Technology Procurement (The Engine): This remains a necessary investment, but it should be viewed as the price of admission—the ticket to enter the race. The focus should be on models and platforms that offer maximum flexibility, robust APIs, and transparent pricing, rather than on all-in-one "black box" solutions that create vendor lock-in.
- Workflow Design & Integration (The Chassis & Pit Crew): This should represent a major and explicit portion of your budget. This is the investment in the architects and engineers who build your modular systems, the integration specialists who connect your data and tools, and the development of the reusable frameworks that will accelerate future projects. This is the investment in your factory.
- User Competency Development (The Driver Academy): This is the most critical, and most frequently underfunded, area of investment. As we argued in “User Competency” section, user skill is a direct multiplier of technological potential. A significant portion of your AI budget must be dedicated to comprehensive, role-specific training programs, the creation of internal centers of excellence, and the cultivation of a community of expert users who can share best practices and drive adoption.
This rebalanced approach forces a crucial strategic question: Are you simply buying a tool, or are you building a lasting organizational capability? The former offers the potential for short-term productivity gains. The latter is how you build a dynasty.
In closing, the journey to mastering generative AI is a marathon, not a sprint. It is a contest of organizational learning, architectural foresight, and strategic discipline. The ultimate goal is not to build a single fast car for a single season. It is to build a championship-winning team—an organization with the culture, the skills, and the systems to adapt, innovate, and win, year after year, no matter how the technology on the track may change. The principles outlined in this paper provide the blueprint for that team. The leadership to build it rests with you.
References
[1] Chui, Michael et al. "The State of AI in 2023: Generative AI's Breakout Year," McKinsey & Company, August 2023. Link
[2] Large Language Model Statistics And Numbers (2025) Link
[3] "Why AI Projects Fail—and What Successful Companies Do Differently," Link
[4] "GPT-4 Technical Report," 2023. Link
[5] "Salesforce Study Warns Against Rushing LLMs into CRM Workflows," Link
[6] Zhang, et al. "Managing Complex Failure Analysis Workflows with LPM-based Agents," Link
[7] "Revolutionizing Enterprise Software: The Ultimate Guide to LLM Integration in 2025" Link
[8] Li, et al. "Adaptable and Precise: Enterprise-Scenario LLM Function-Calling Capability Training Pipeline" Link
[9]"Beyond the Hype: Creating Measurable ROI with LLM Implementations," Link
Download the Full Paper
Get the PDF version with complete references and detailed case studies for offline reading and sharing.
Developed by Aide Solutions LLC. This white paper was prepared with the support of generative artificial intelligence tools. The author reviewed, edited, and takes full responsibility for the content and conclusions presented. Full references are available in the PDF version.