Executive Summary
Large Language Models have demonstrated remarkable capabilities, but they face a critical knowledge gap within the enterprise. They lack access to proprietary, domain-specific, or real-time data, which limits their utility and introduces the risk of generating inaccurate or "hallucinated" responses. Retrieval-Augmented Generation (RAG) has emerged as one of the key architectures to solve this by connecting LLMs to authoritative data sources.
However, the initial, simple implementations of RAG are proving insufficient for complex, production-grade applications. They suffer from low-precision retrieval, an inability to handle conversational context, and inefficiency at scale.
This white paper provides a blueprint for moving beyond these limitations — a multi-stage, advanced RAG workflow designed for accuracy, relevance, and efficiency, built on high-quality data ingestion, intelligent query analysis, hybrid search, LLM-based re-ranking, and stateful conversational memory.
Key Takeaway
Enterprise-grade RAG is not a simple API call. It is a carefully architected data and application workflow. By adopting advanced strategies, organisations can transform AI from a promising prototype into a reliable, high-impact business capability.
1. Introduction: Understanding "RAG"
The term "Retrieval-Augmented Generation" is rapidly becoming as broad and multifaceted as "Artificial Intelligence" itself. It is not a single, monolithic technology but a design philosophy for grounding LLMs in fact-based, external knowledge. As organisations move from experimentation to implementation, it's crucial to understand the spectrum of sophistication that exists under the RAG umbrella. Implementations can be categorised into three distinct levels:
- Naive RAG: The simple, proof-of-concept model — embed the user query, perform a vector search against data chunks, feed the top results to an LLM. Excellent for demonstrations, this approach quickly breaks down when faced with real-world complexity.
- Advanced RAG: A move from a simple pipeline to a modular, multi-stage process. It introduces steps before and after the retrieval phase: query analysis, re-ranking search results for relevance, and hybrid search techniques. This is the minimum requirement for a production-level system.
- Bespoke RAG Workflows: The pinnacle of RAG architecture — a stand-alone, problem-specific application designed to solve a unique business challenge. These workflows incorporate conditional logic, conversational memory, and can decide dynamically which tools or data sources to use based on the user's query and interaction history.
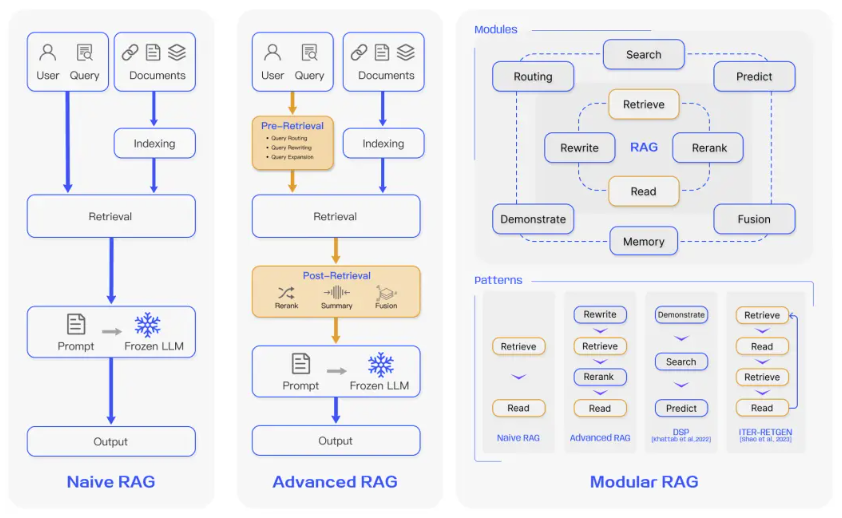
In this paper, I will guide you through the principles and components required to build from a naive prototype toward a bespoke, intelligent workflow.
2. The Unseen 80%: Data Quality and Ingestion Strategy
The most advanced retrieval pipeline cannot save a project built on a poor data foundation. "Garbage in, garbage out" has never been more relevant than in RAG systems. The quality, structure, and metadata of your ingested information directly dictate the performance ceiling of your entire RAG system. A robust ingestion strategy is therefore not an optional preparatory step but a core pillar of the architecture.
2.1 Strategic Information Extraction
Enterprise data rarely arrives in clean, text-only formats. It is often locked within complex, unstructured documents — PDFs with multi-column layouts, figures, and formatting artifacts. A successful ingestion process must strategically parse these documents to extract pure, high-value information while discarding noise.
2.2 Metadata: The Key to Efficient Retrieval
During the ingestion process, it is critical to extract or generate rich, structured metadata for every piece of data. This metadata acts as a set of powerful "hooks" that the retrieval system can use to narrow down the search space before performing an expensive vector search — known as pre-retrieval filtering. Essential metadata includes:
- Document source, title, and creation date
- Author, department, or business unit
- Document section or subsection headers
- Key entities (people, products, dates) mentioned in the text
2.3 Intelligent Chunking and Post-Processing
Simply splitting documents into fixed-size chunks is crude and often ineffective — it results in chunks that are semantically incomplete or contain a mix of relevant and irrelevant information. A more intelligent approach is content-aware chunking, which splits documents along logical boundaries like paragraphs, sections, or presentation slides.
A crucial Chunk Quality Control step should be implemented after chunking:
- Cleaning: Removing boilerplate text like headers, footers, and page numbers
- Enriching: Adding a concise summary or a list of keywords to each chunk's metadata
- Validating: Discarding chunks that do not meet a minimum threshold for information content

3. Beyond the Prototype: Why Basic RAG Fails at Scale
While a naive RAG pipeline is a powerful tool for demonstrations, its architectural simplicity reveals significant weaknesses when deployed in a demanding enterprise environment. Four common failure points erode user trust and limit the system's value:
The "Needle in a Haystack" Problem
Enterprise knowledge bases are vast and noisy. When a user asks a conceptually broad question, a simple vector search often returns a wide array of marginally relevant results. The LLM is then forced to synthesise an answer from a context diluted with low-quality or irrelevant information, leading to generic, unhelpful, or incorrect responses.
The Context-Deficit Problem
Human conversation builds on history; naive RAG does not. Consider: a user asks "What is the approval date of treatment X?" and the system answers. If the follow-up question is "Which company made it?" a naive RAG system treats this as a brand new query with no memory of the prior context. The result is a frustrating, disjointed experience.
The Precision-Recall Trade-off
A simple keyword search misses conceptual matches; a simple semantic search misses exact-term matches. Neither alone is sufficient for enterprise retrieval that must be both comprehensive and precise.
The Inefficiency Trap
Simple RAG runs the full retrieval pipeline for every query, even straightforward follow-up questions that could be answered from conversation history. This wastes compute resources and increases latency and cost.
4. The Advanced RAG Workflow: A Component-by-Component Breakdown
4.1 Pre-Retrieval: Query Analysis and Optimisation
The advanced workflow begins before any search is performed. A fast, efficient LLM acts as a Query Analyser, parsing the user's raw input to understand intent and optimise the query for maximum retrieval effectiveness. This involves query rewriting (clarifying ambiguous phrasing), query decomposition (breaking a multi-part question into sub-queries), and query expansion (adding synonyms and related terms).
4.2 Retrieval: Hybrid Search Strategy
The advanced workflow employs two complementary search methods in parallel. Vector (Semantic) Search finds information based on conceptual meaning and intent — answering "what documents are about this topic?" Keyword (Lexical) Search is optimised for exact matches of specific terms — product codes, names, unique identifiers. By combining both, the system captures both the conceptual "forest" and the specific "trees."
4.3 Post-Processing: LLM-Based Re-ranking and Context Formatting
A hybrid search provides a rich set of candidate documents, but not all are equally valuable. A fast LLM acts as a Re-ranker — evaluating each retrieved chunk against the refined user query and assigning a relevance score. This achieves two goals: prioritisation (ensuring the most direct information is placed first in the context window) and noise reduction (discarding low-quality or irrelevant chunks that would distract the final generation LLM).
4.4 Introducing State: Conversational Memory and Conditional Logic
The final and most sophisticated evolution is to make the RAG system stateful — transforming it from a simple request-response tool into a true conversational partner. This is achieved through two mechanisms:
- Chat History: The system maintains a short-term memory of recent queries and answers. When a new query arrives, this history is provided as additional context to the Query Analyser, allowing it to understand pronouns and follow-up questions.
- The Search Decision Node: Before launching the full retrieval process, an LLM makes a conditional decision: "Can the user's current question be answered using only the chat history?" If yes, the system bypasses the expensive search and proceeds directly to answer generation. If no, it runs the full workflow. This makes the system smarter, faster, and more cost-effective.
5. The Evolving Landscape of RAG
The advanced workflow described in this paper represents the current state of the art for production-grade RAG. However, the field continues to evolve rapidly. Three key frontiers promise to further enhance RAG capabilities:
- Agentic RAG: Systems that are not just passive retrievers but active agents that can perform multi-step reasoning, rephrase queries when retrieval fails, ask clarifying questions, query different data sources, or conduct online searches. This introduces a dynamic reasoning loop that more closely mimics human problem-solving.
- Graph RAG: Leveraging knowledge graphs — databases of nodes (entities) and edges (relationships) — to answer complex relational queries. Instead of retrieving text chunks, the system traverses the graph to find connections, patterns, and hierarchies across entities.
- Multi-modal RAG: Extending beyond text to incorporate and reason over diverse data types — images, charts, tables within documents, audio, or video clips. A user might upload a diagram and ask the system to retrieve troubleshooting documents related to a specific component shown in the image.
6. Conclusion: RAG as a Core Business Capability
The journey from a naive prototype to a sophisticated, production-ready RAG system is one of increasing architectural intelligence. By embracing a stateful workflow, it is possible to build AI systems that are accurate, context-aware, and highly efficient.
By investing in this robust approach, organisations can move past the limitations of basic RAG and realise the true potential of their proprietary data:
- Increased accuracy and user trust, leading to higher adoption rates
- Significant operational efficiency through reduced wasted computation and faster answers
- The ability to unlock deep, actionable insights previously hidden within vast stores of unstructured information
Ultimately, Retrieval-Augmented Generation is more than a technical pattern — it is a core business capability that empowers organisations to build truly intelligent applications that learn from their own data and drive measurable value.
Download the Full Paper
Get the PDF version for offline reading and sharing with your team.
Developed by Aide Solutions LLC. Portions of this paper were drafted with the assistance of an LLM.